Para ver el efecto que tiene, por ejemplo, el no limitar la profundidad máxima de los modelos entrenados, realicemos el mismo ejercicio que hicimos con los árboles de decisión: entrenemos 15 Random Forest limitando su profundidad máxima:
train_scores = []
test_scores = []
for depth in range(1, 16):
model = RandomForestClassifier(max_depth = depth)
model.fit(X_train, y_train)
train_scores.append(model.score(X_train, y_train))
test_scores.append(model.score(X_test, y_test))
test_scores = []
for depth in range(1, 16):
model = RandomForestClassifier(max_depth = depth)
model.fit(X_train, y_train)
train_scores.append(model.score(X_train, y_train))
test_scores.append(model.score(X_test, y_test))
Visualicemos ahora el resultado:
fig, ax = plt.subplots(figsize = (8, 4.8))
ax.plot(range(1, 16), train_scores, label = "Train dataset")
ax.plot(range(1, 16), test_scores, label = "Test dataset")
ax.set_xticks(range(1, 16), labels = range(1, 16))
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_ylim(0, 1)
ax.legend()
plt.show()
ax.plot(range(1, 16), train_scores, label = "Train dataset")
ax.plot(range(1, 16), test_scores, label = "Test dataset")
ax.set_xticks(range(1, 16), labels = range(1, 16))
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_ylim(0, 1)
ax.legend()
plt.show()
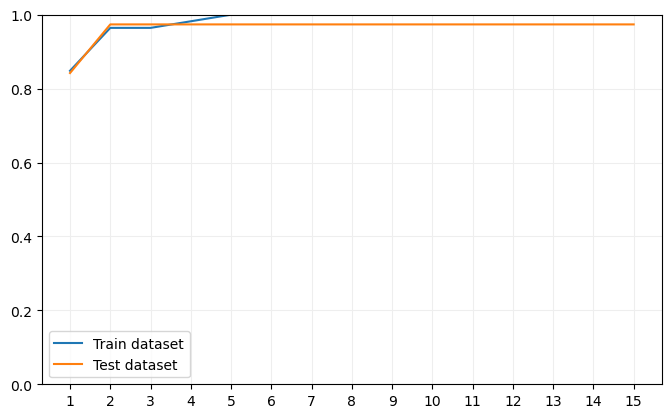
Podemos comprobar que los porcentajes de muestras bien clasificadas es muy elevado tanto en el dataset de entrenamiento como en el de validación, y que este último no decae a partir de una cierta profundidad máxima como sí ocurría con los árboles de decisión. Y ésta es una importante característica de Random Forest: su tendencia al sobreentrenamiento es muy pequeña.