Si se trata, por ejemplo, de arrays bidimensionales, los elementos correspondientes a cada índice ya no son escalares, sino arrays unidimensionales (filas).
Partamos, por ejemplo, de este array de ejemplo (generado con la función integrada de Python range y redimensionado con la función numpy.reshape que veremos más adelante):
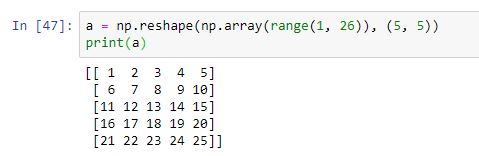
Recordando que los elementos principales del iterable utilizado para crear el array son interpretados como filas, podemos utilizar un único índice para extraer una de estas filas:

Al tratarse estos resultados de arrays, podemos volver a realizar selecciones en ellos:

NumPy nos permite usar un único par de corchetes, separando estos índices por comas, haciendo la selección mucho más simple:
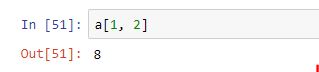
Estos índices pueden ser rangos del tipo a:b. En el siguiente ejemplo estamos extrayendo los elementos que pertenecen a las filas 1 y 2 y columna 3 (recordemos que los índices comienzan en cero):

En este otro ejemplo estamos seleccionando los elementos que pertenecen a las filas 1 y 2, y columnas 2 y 3:
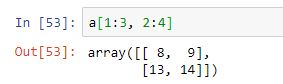
Como ya sabemos, si en un rango se omite el primer valor, se toma el valor cero por defecto. Y si se omite el segundo valor, se consideran todos los elementos hasta el final. Así, en el siguiente ejemplo se extraen los elementos de las filas 0, 1 y 2, y columnas 3 y 4:
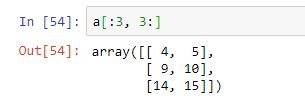
Y, por supuesto, si en un rango se omiten los dos valores, se consideran todos los elementos disponibles:
