El diagrama de caja, también conocido como diagrama de caja y bigote o box plot, resume la distribución de los datos mostrándonos la posición de sus cuartiles y de los valores atípicos (outliers). Se muestra en seaborn con la función seaborn.catplot y el argumento kind = "box" o con la función seaborn.boxplot. Por defecto, tras calcular la mediana y los cuartiles Q1 y Q3, se calcula el conocido como rango intercuantil (Q3 - Q1). Los "bigotes" o "whiskers" (la línea que sale de la caja) se extienden hasta cubrir 1.5 veces el rango intercuantil por debajo y por encima de Q1 y de Q3, respectivamente. Todos los puntos fuera de este rango son considerados valores atípicos y son mostrados como puntos individuales:
sns.catplot(x = "day", y = "tip", data = tips, kind = "box");
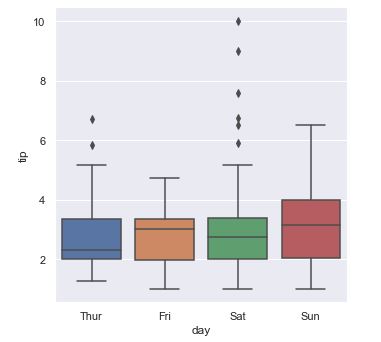
En el anterior gráfico distinguimos los cuartiles Q1 y Q3 (límites superior e inferior de las "cajas", distancia a la que nos hemos referido como rango intercuantil), la mediana (línea horizontal dentro de la caja) y los valores considerados "normales" entre los topes superior e inferior de las líneas verticales (los topes representan 1.5 veces el rango intercuantil). Fuera de estos límites vemos los outliers o valores anómalos.
La distancia más allá de la cual un valor se considera anómalo se puede personalizar con el parámetro whis. Éste toma, por defecto, el mencionado valor de 1.5. Obsérvese cómo cambia la gráfica si aumentamos este valor a, por ejemplo, 3:
sns.catplot(x = "day", y = "tip", data = tips, kind = "box", whis = 3);
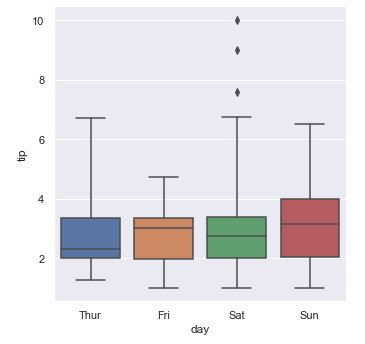
Ahora, los valores que eran outliers en la primera gráfica para el jueves ya son todos considerados normales. Y los outliers del sábado también han disminuido en número de forma considerable.
En este tipo de gráfica seguimos teniendo acceso al parámetro hue:
sns.catplot(x = "day", y = "tip", data = tips, kind = "box", hue = "sex");

Vemos que, si en la categoría de "diagramas de dispersión categóricos" se mostraba cada punto de un color distinto, ahora que se está agregando la información, la alternativa es dividir cada caja según los valores que tome la categoría que se indique ("sex", en este caso).
De todas formas, este enfoque está limitado por el número de valores posibles que tome dicha categoría. En el ejemplo anterior eran dos valores: Male y Female, pero veamos el resultado si utilizamos como variable de segmentación "size", representando el número de comensales:
sns.catplot(x = "day", y = "tip", data = tips, kind = "box", hue = "size");

Aun cuando seaborn hace un bastante buen trabajo mostrando las cajas para cada valor de la variable de segmentación, la interpretación de la gráfica comienza a resultar más compleja. Una opción, por supuesto, es aumentar el tamaño de la figura:
sns.catplot(x = "day", y = "tip", data = tips, kind = "box", hue = "size", aspect = 2);
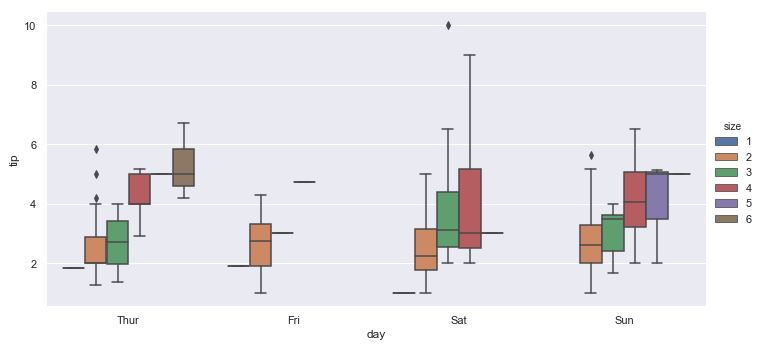
...o recurrir a los "facets" (mostrar en diferentes gráficas los datos correspondientes a cada valor de la variable categórica):
sns.catplot(x = "day", y = "tip", data = tips, kind = "box", col = "size", col_wrap = 3);
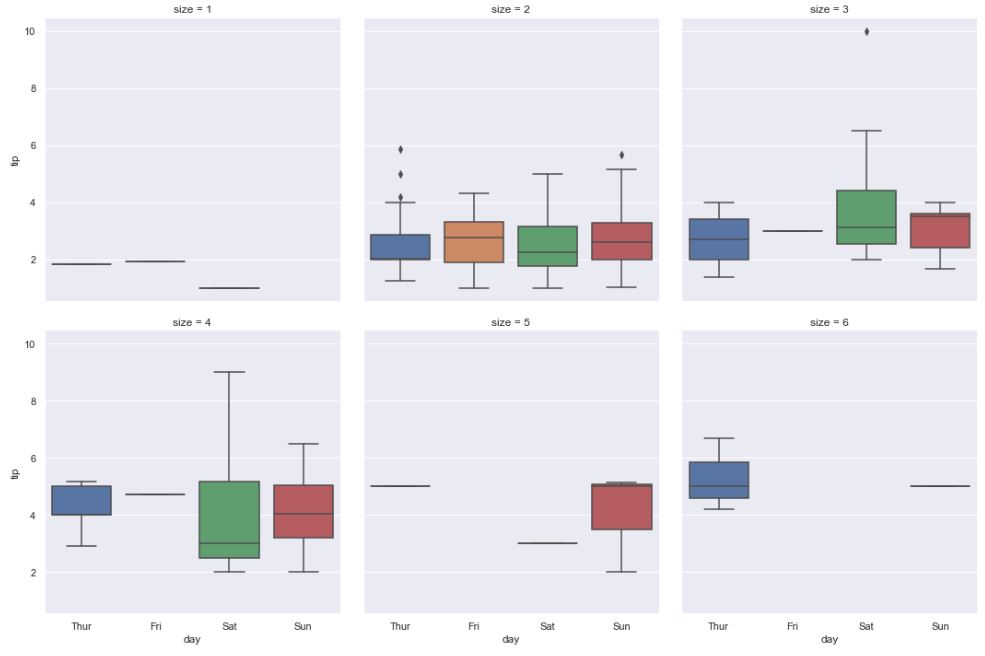
En la visualización anterior se ha recurrido a mostrar las gráficas con un máximo de tres por fila usando el parámetro col_wrap ya visto.
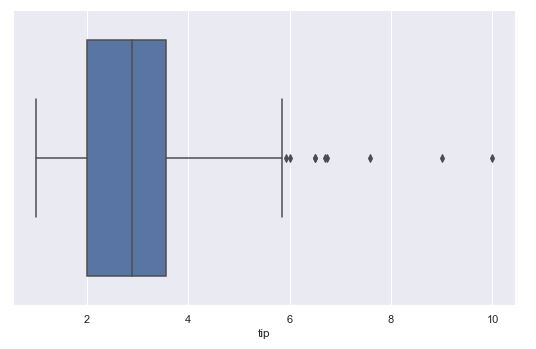
Y nada nos impide utilizar esta función con una única variable, mostrándose su distribución:
sns.catplot(x = "tip", data = tips, kind = "box", aspect = 1.5);