Consideremos los valores mostrados en las secciones anteriores para el DataFrame X y la Serie Pandas y:
X = pd.DataFrame(np.array([5, 0, 3, 3, 7, 3, 5, 2, 4, 7, 6, 8, 8, 1, 6]).reshape(3, -1))
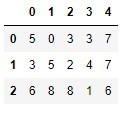
X
y = pd.Series([0, 4, 1])
y
0 0
1 4
2 1
dtype: int64
Ya sabemos cuáles serían las listas x_train e y_train:
x_train = [x.values.reshape(-1, 1) for (i, x) in X.iterrows()]
x_train
[array([[5],
[0],
[3],
[3],
[7]]),
array([[3],
[5],
[2],
[4],
[7]]),
array([[6],
[8],
[8],
[1],
[6]])]
y_train = [to_categorical(n, 10) for n in y]
y_train
[array([[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]]),
array([[0.],
[0.],
[0.],
[0.],
[1.],
[0.],
[0.],
[0.],
[0.],
[0.]]),
array([[0.],
[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]])]
La variable training_data contendrá, por lo tanto, la siguiente lista de tuplas:
training_data = [(x, y) for (x, y) in zip(x_train, y_train)]
training_data
[(array([[5],
[0],
[3],
[3],
[7]]),
array([[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]])),
(array([[3],
[5],
[2],
[4],
[7]]),
array([[0.],
[0.],
[0.],
[0.],
[1.],
[0.],
[0.],
[0.],
[0.],
[0.]])),
(array([[6],
[8],
[8],
[1],
[6]]),
array([[0.],
[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]]))]
Extraigamos la primera tupla:
training_data[0]
(array([[5],
[0],
[3],
[3],
[7]]),
array([[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]]))
Efectivamente contiene las características predictivas de la primera muestra (los valores 5, 0, 3, 3 y 7) y la versión categorizada de la variable objetivo (0).