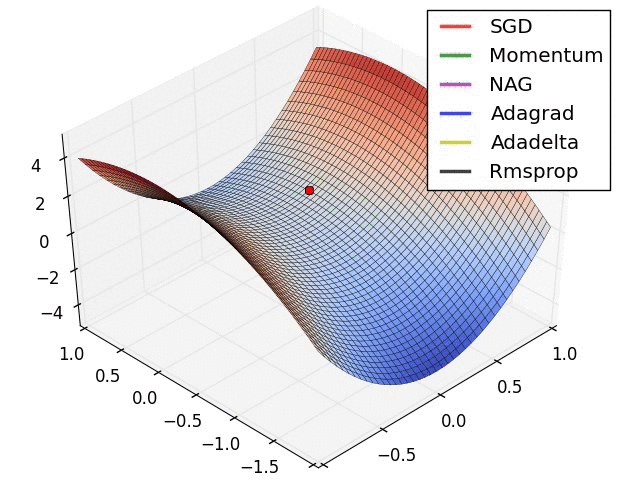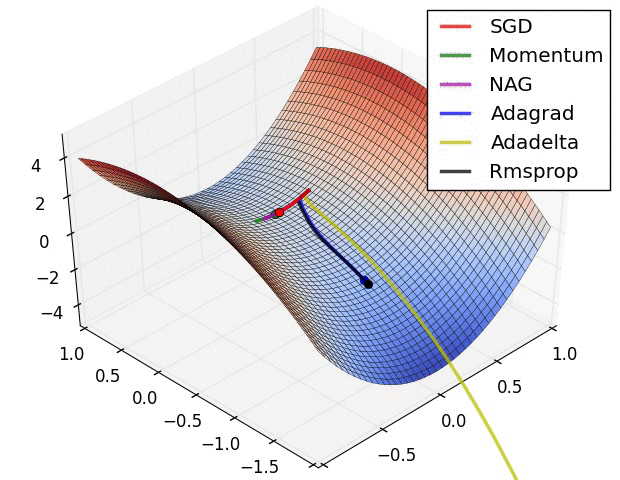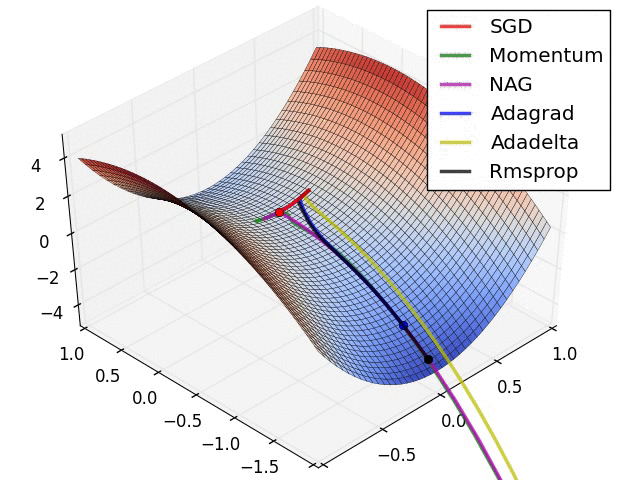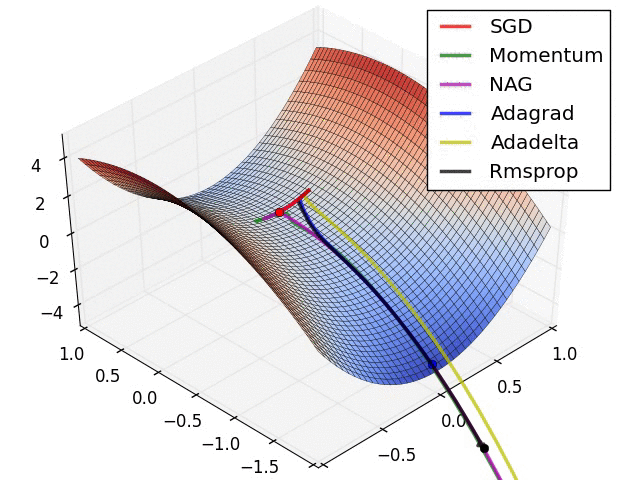
Fuente: https://imgur.com/a/Hqolp
La situación mostrada en la imagen anterior es un tanto rebuscada pues, en una de las dimensiones del punto de partida la derivada es cero. Vemos cómo el optimizador SGD (Stochastic Gradient Descent) no consigue encontrar el camino de descenso. AdaGrad y RMSprop se muestran más lentos que el resto de optimizadores. En NAG (Nesterov Accelerated Gradient) y Momentum la inercia aplicada hace que, tras arrancar con incrementos bajos, éstos aumenten rápidamente.