AdaBoost entrena de forma secuencial un conjunto de aprendices débiles a partir de un algoritmo base común. Todos los aprendices son entrenados con el mismo conjunto de datos pero éstos van recibiendo pesos que dependen de los errores cometidos por cada aprendiz. Así, inicialmente todos las muestras reciben un peso inicial wi de 1/n (suponiendo que haya n muestras). El primer aprendiz es entrenado y se estima su tasa de error. Suponiendo que estemos trabajando en un problema de clasificación, esta tasa de error (en general, para el aprendiz j-ésimo) sería:

Si no ha habido muestras mal clasificadas, esta tasa de error será 0. Por el contrario, si todas las muestras han sido mal clasificadas, esta tasa será 1.
A continuación, el aprendiz recibe un peso que será tenido en cuenta al final del proceso para estimar una predicción final. Este peso viene dado por la siguiente función:
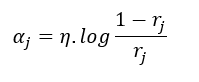
Esta función, para diferentes valores de η, tiene la siguiente forma:
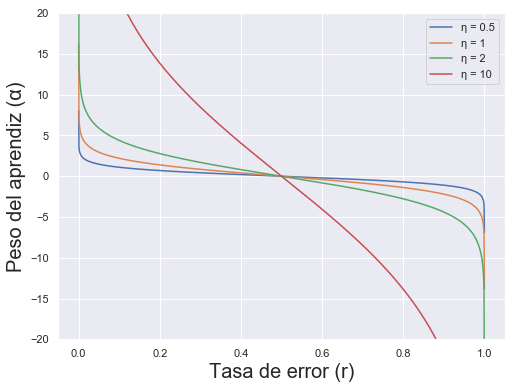
Como vemos, cuanto menor es la tasa de error, mayor será el peso que el aprendiz reciba (en el límite, un error de 0 supone un peso infinito). η es la llamada tasa de aprendizaje, o learning rate, que determina la contribución de cada aprendiz: una tasa de aprendizaje menor supone una menor variación en los pesos asignados aun cuando el rendimiento haya sido muy diferente. Por el contrario, una tasa de aprendizaje mayor supone que pequeños cambios en la tasa de error se plasme en pesos muy diferentes.
Una vez entrenado el aprendiz y calculada su tasa de error y peso relativo, se actualizan los pesos de las muestras de forma que aquellas para las que la predicción fue incorrecta vean incrementado su peso:

Es decir, las muestras bien clasificadas no ven modificado su peso. Por el contrario, aquellas mal clasificadas ven su peso multiplicado por la exponencial del peso del aprendiz. Esta función tiene la siguiente forma:
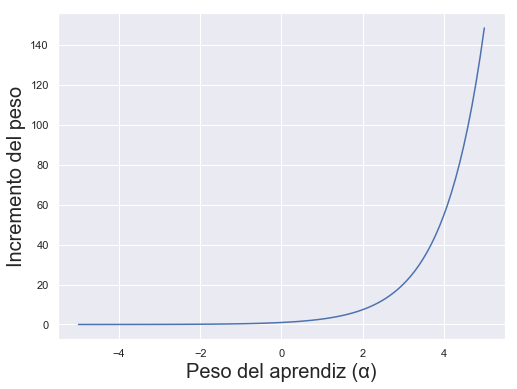
Obsérvese que, cuando el aprendiz ha tenido un muy mal comportamiento (cuando su tasa de error ha sido próxima a 1, lo que supone un peso del aprendiz negativo), los pesos de las muestras mal clasificadas son multiplicados por valores próximos a cero. En circunstancias normales, con una tasa de error del aprendiz inferior a 0.5, las muestras mal clasificadas ven multiplicado su peso por un valor superior a 1 (mayor cuanto mayor haya sido el peso del aprendiz, según la gráfica anterior).
Una vez actualizados los pesos de las muestras, se normalizan dividiéndolos por la suma total de los pesos.
De esta forma, el siguiente aprendiz se ve obligado a concentrarse en aquellas muestras que hayan resultado más difíciles para el aprendiz anterior (aquellas con pesos mayores).
Cuando todos los aprendices han sido entrenados, AdaBoost realiza la predicción final dando a cada aprendiz un voto ponderado según el peso relativo que haya recibido.
Scikit-learn implementa este tipo de ensamblado en las clases sklearn.ensemble.AdaBoostClassifier y sklearn.ensemble.AdaBoostRegressor.