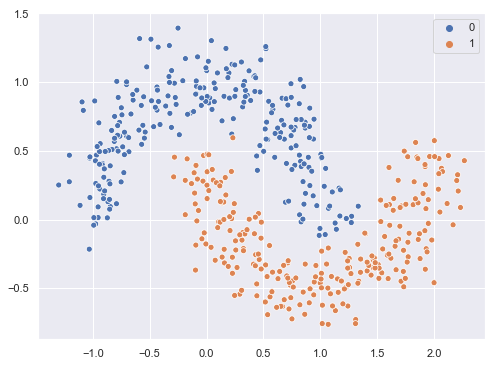
Probemos el algoritmo AdaBoostClassifier con el dataset "Moons" de Scikit-learn tomando como modelo base un árbol de decisión. Cargamos las librerías, los datos y los mostramos en una gráfica:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
X, y = make_moons(500, noise = 0.15)
plt.figure(figsize = (8, 6))
sns.scatterplot(X[:, 0], X[:, 1], hue = y);
Calculamos como referencia el score de un simple árbol de decisión (obsérvese que es de profundidad 8):
tree = DecisionTreeClassifier(max_depth = 8, random_state = 0)
cross_val_score(tree, X, y, cv = 5).mean()
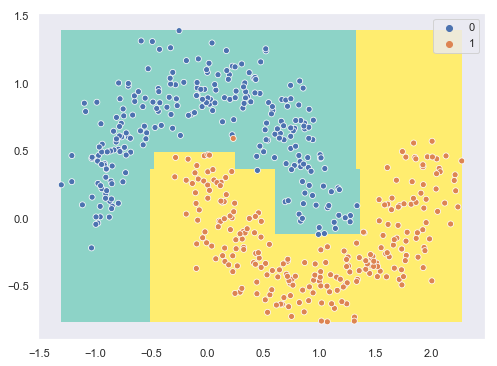
Mostramos la gráfica anterior indicando las áreas que reciben cada una de las predicciones:
cx = np.linspace(min(X[:, 0]), max(X[:, 0]), 100)
cy = np.linspace(min(X[:, 1]), max(X[:, 1]), 100)
xx, yy = np.meshgrid(cx, cy)
def output_single_tree(model, x, y):
sample = np.array([x, y]).reshape(-1, 2)
prediction = model.predict(sample)
return prediction[0]
output_tree = np.vectorize(output_single_tree)
tree.fit(X, y)
zz = output_tree(tree, xx, yy)
plt.figure(figsize = (8, 6))
plt.pcolormesh(cx, cy, zz, cmap = "Set3");
sns.scatterplot(X[:, 0], X[:, 1], hue = y);
Ahora instanciamos el algoritmo AdaBoost considerando 100 aprendices de tipo árbol de decisión de profundidad 2:
adaboost = AdaBoostClassifier(
DecisionTreeClassifier(max_depth = 2, random_state = 0),
100,
learning_rate = 1,
random_state = 0
)
cross_val_score(adaboost, X, y, cv = 5).mean()
En este caso particular el score es semejante al del árbol de decisión (recordemos que estamos comparando el ensamblado con un árbol de profundidad 8). Si mostramos en una gráfica las áreas que reciben las diferentes predicciones:
def output_single_adaboost(x, y):
sample = np.array([x, y]).reshape(-1, 2)
prediction = adaboost.predict(sample)
return prediction
output_adaboost = np.vectorize(output_single_adaboost)
adaboost.fit(X, y)
zz = output_adaboost(xx, yy)
plt.figure(figsize = (8, 6))
plt.pcolormesh(cx, cy, zz, cmap = "Set3");
sns.scatterplot(X[:, 0], X[:, 1], hue = y);
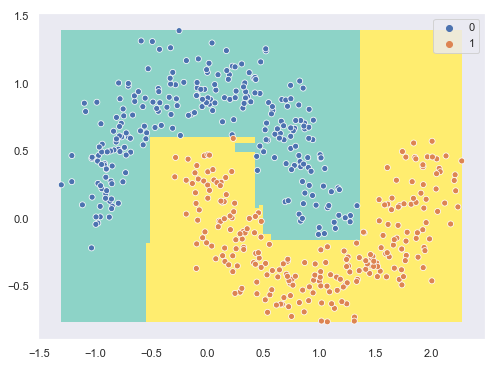
...vemos que el perfil de las áreas de decisión es algo más complejo que el obtenido con el árbol de decisión aunque el score final haya sido semejante.