Animados por la buena evolución del resultado a medida que aumentamos el grado del polinomio, nos decidimos entonces a usar un polinomio de grado 16, que imaginamos que se adaptará mucho mejor a nuestros datos:
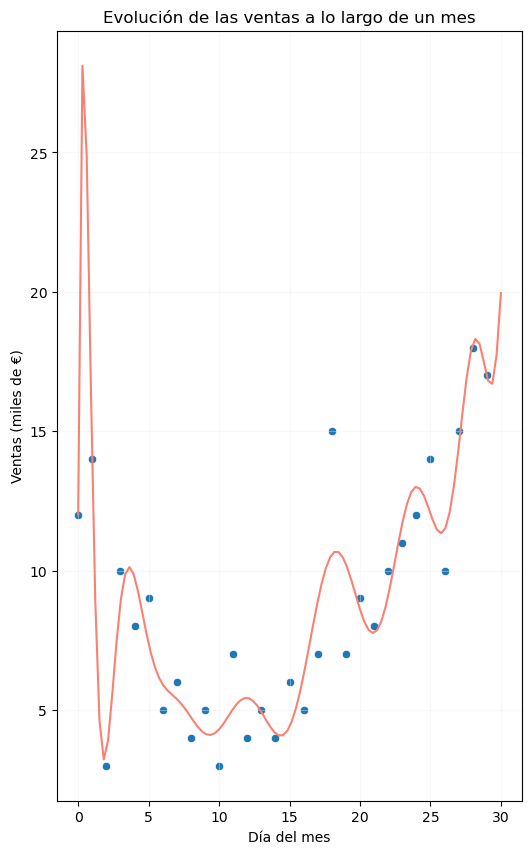
Y una cosa es cierta: este polinomio se ajusta mucho mejor a los datos de los que partimos para el análisis (de hecho, el polinomio pasa exactamente por encima de muchos de los puntos). Desde un punto de vista matemático no hay dudas de que este resultado es mucho mejor que los anteriores, pero ¿tiene sentido desde un punto de vista de negocio?, ¿de verdad vamos a pensar que entre el día 1 y el día 2 vamos a tener algún momento en el que se venderán productos por casi 30 mil euros? Evidentemente no: hemos ajustado tanto la curva a nuestros datos de entrenamiento que hemos perdido la capacidad de generalizar el resultado.
Decimos en un caso como éste que el modelo ha sido sobreentrenado ("overfitted" en la literatura en inglés). Con toda probabilidad, si dispusiéramos de datos de validación (por ejemplo, si conociéramos las ventas del mes siguiente al considerado en el análisis) y probásemos el modelo en ellos, podríamos confirmar que se ajusta muy mal a estos datos, y éste es el mejor síntoma del sobreentrenamiento: un modelo sobreentrenado se ajusta muy bien a los datos de entrenamiento, pero muy mal a los datos de validación. O, dicho con otras palabras, ha "memorizado" los datos de entrenamiento perdiendo capacidad de predecir resultados para datos no conocidos.