La función pandas.merge nos permite realizar "joins" entre tablas. El join es realizado sobre las columnas o sobre las filas. En el primer caso, las etiquetas de las filas son ignoradas. En cualquier otro caso (joins realizado entre etiquetas de filas, o entre etiquetas de filas y de columnas), las etiquetas de filas se mantienen.
Veamos un primer ejemplo. Partimos de dos tablas conteniendo las ventas y costes de producción para varios meses:

Vemos que ambos dataframes tienen una columna común ("Month") y varias filas comunes ("ene", "feb" y "mar"). Obsérvese que en df2 las filas no están ordenadas y que, en df1, el mes de enero tiene índice 0 mientras que, en df2, el mes de enero tiene índice 1.
Si aplicamos la función merge a estos dataframes con los valores por defecto, obtenemos el siguiente resultado:
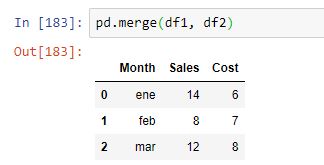
Esos valores por defecto suponen que el join se realiza sobre las columnas comunes y tipo "inner" (considerando solo las filas con etiquetas comunes).
Si especificamos que el join sea de tipo "outer", lo que definimos con el parámetro how, el resultado considerará todas las etiquetas presentes en ambos dataframes:
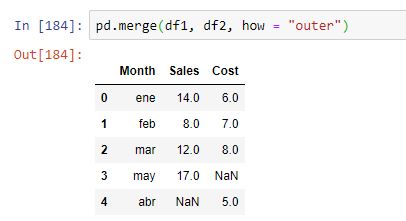
Como vemos, se ha rellenado con NaN's los valores inexistentes. Otras opciones para el parámetro how son "left" y "right" (además de la opción por defecto, "outer").
Ya se ha comentado que, por defecto, el join se realiza entre las columnas comunes. Esto es, sin embargo, controlable usando el parámetro on y especificando la columna o columnas a usar. Por ejemplo, consideremos los siguientes dataframes:
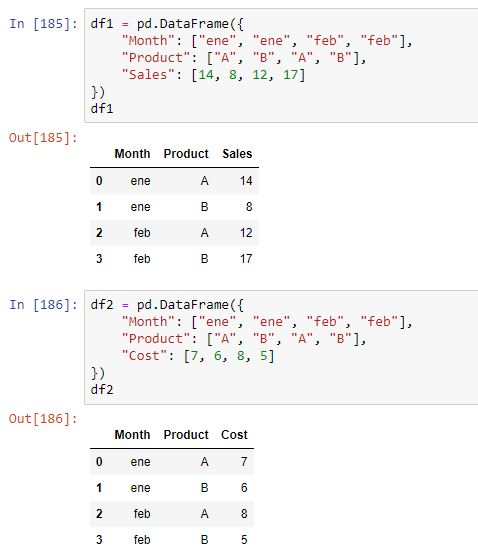
Hay dos columnas comunes, lo que supone que el resultado de un merge por defecto sería el siguiente:
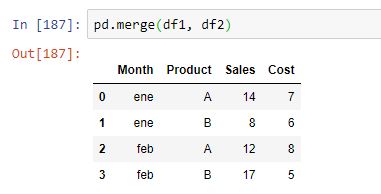
Es decir, para cada combinación de Mes-Producto se añadirían los valores de los campos de ventas y coste. Si quisiéramos que el join se realizase solo por uno de los campos, Product, por ejemplo, bastaría con especificarlo con el parámetro on:
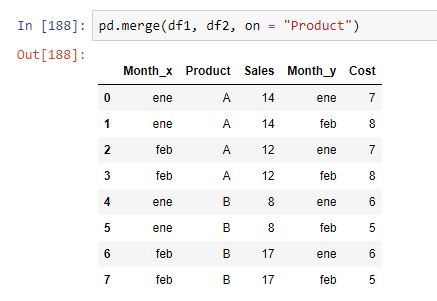
Además del campo utilizado para realizar el join ("Product"), al existir un campo común a ambos dataframes ("Month") que no se desea usar para el join, pandas añade un sufijo (configurable) a este campo en ambas tablas para poder diferenciarlo.
También podría ocurrir que ambos dataframes no tuviesen columnas comunes (columnas con el mismo nombre) pero que, aun así, quisiéramos realizar el join por algunas de ellas. Por ejemplo:

Al no haber columnas comunes, la ejecución de la función merge devolvería un error. En este caso podemos usar los parámetros left_on y right_on para especificar el campo a usar en la tabla de la izquierda del join y en la de la derecha, respectivamente:
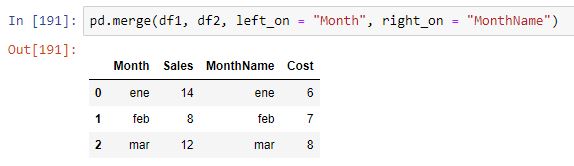
Vemos cómo se realiza el join correctamente y se mantienen las columnas originales.