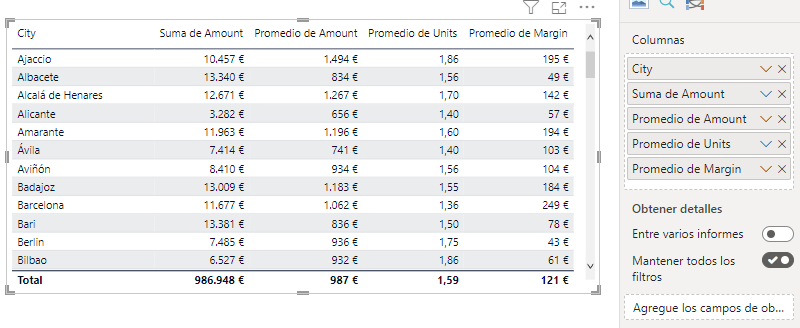
El acceso al algoritmo KMeans en el gráfico de dispersión tiene una gran limitación, y es que, como hemos visto, el número de métricas involucradas está limitado a tres. Para solucionar este problema también tenemos acceso al mismo algoritmo en el objeto visual Tabla y, en este caso, el número máximo de métricas pasa a ser quince.
Para probar esta opción vamos a crear una tabla en nuestro informe a la que vamos a llevar el campo Amount con la función de agregación Suma, el campo Amount (de nuevo) con la función de agregación Promedio, el campo Units con la función de agregación Promedio, y el campo Margin con la función de agregación Promedio.
Y vamos a desagregar nuestra tabla por ciudad, para lo que llevamos el campo City de la tabla Geography a la tabla asegurándonos de que no se está aplicando ninguna función de agregación sobre él.
Se han escogido estas métricas como simple ejemplo y se ha implicado el campo Amount dos veces solo para recalcar que un mismo campo puede estar implicado en una o más métricas: