Para probar este algoritmo vamos a crear un gráfico de dispersión en el que se muestre el valor medio de la cifra de ventas (campo Amount con la función de agregación Promedio) versus el valor medio del número de unidades vendidas (campo Units con la misma función de agregación), desagregado por ciudad (campo City de la tabla Geography):
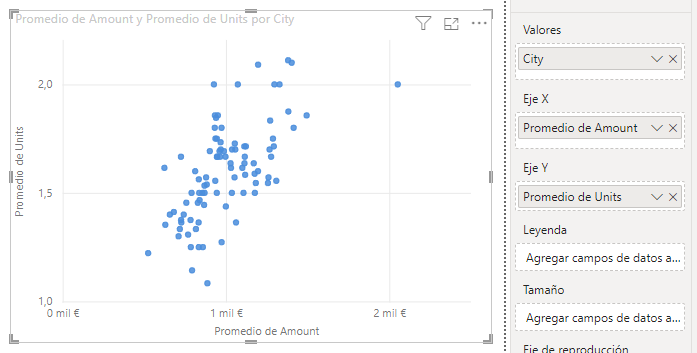
Nuestra intención es agrupar las ciudades según su parecido y hacerlo de forma no supervisada. En este caso estamos involucrando en el objeto visual el valor medio del importe de ventas y el valor medio del número de unidades vendidas, de forma que, en este escenario, dos ciudades se parecen si dichos valores son semejantes.