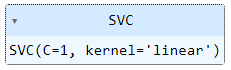
Entrenemos el modelo con el mismo coeficiente de regularización que usamos para las muestras linealmente separables:
model = SVC(kernel = "linear", C = 1)
model.fit(X, y)
model.fit(X, y)
Mostremos la frontera de decisión:
show_boundaries(model, X, None, y, None, iris.species.unique())
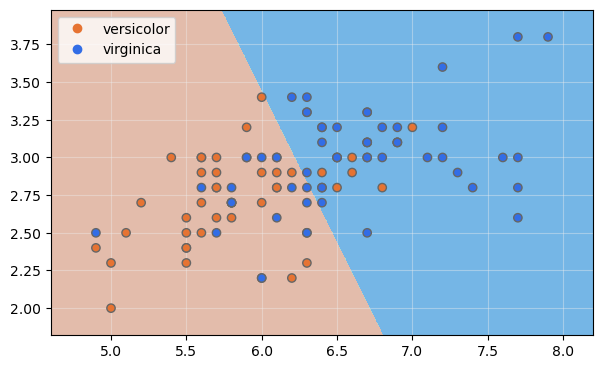
El número de muestras mal clasificadas es, tal y como podríamos esperar, bastante elevado. De hecho, si mostramos el margen y los vectores de soporte:
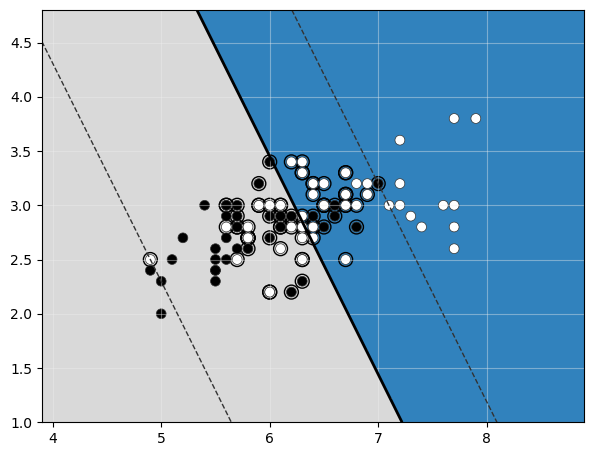
comprobamos que el margen incluye a la mayor parte de las muestras.