In this scenario we start from the following data table:
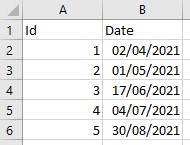
Note that in the table the dates are shown in order (from oldest to most modern) to make their interpretation easier, but keep in mind that this might not be the case.
The objective is to create a calculated column that tells us, for each row, how many rows of the same table contain dates prior to the one of the row being considered (taking into account, as has been commented, that the rows could be not ordered according to the date).
As we want to add a calculated column, a row context will be created by default for each of the evaluated rows. That is, for the first row (the one corresponding to the field Id 1) a row context will be created in which we can access the values of its fields, Id and Date. From the value of the Date field we would like to filter the table so that only the rows with previous dates are considered, and count the number of resulting rows.
In pseudo code it would be something like this:
COUNTROWS(
FILTER(
data,
data[Date] < current-row-date
)
)
The current-row-date tag has been used to refer to the value of the Date field of the row being considered.
The FILTER function, being an iterator, will create a new row context in which to evaluate the condition for each row of the data table:
Logically, the following code would not work:
COUNTROWS(
FILTER(
data,
data[Date] < data[Date])
)
)
...because within the row context created by FILTER, the value of data[Date] is the value of the Date field of the row that FILTER is iterating. What we would like is for the current-row-date value to be the one defined in the "previous" row context, the one created by the calculated column prior to executing the FILTER function.
For this we have two solutions:
The first -the only one that existed until the variables were introduced in DAX in 2015- is to use the EARLIER function. This function returns exactly what we want: the value of a field for a previous row context (allowing us to indicate how many row contexts to go back). For example:
COUNTROWS(
FILTER(
data,
data[Date] < EARLIER(data[Date], 1)
)
)
...would return the result we were looking for:
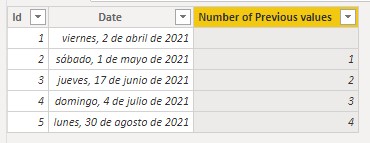
We see that, for the first row, the function returns a Blank since there are no rows with previous dates and the COUNTROWS function returns this value for empty tables. We can force a 0 to be returned in this case using the COALESCE function:
COALESCE(
COUNTROWS(
FILTER(
data,
data[Date] < EARLIER(data[Date], 1)
)
),
0
)
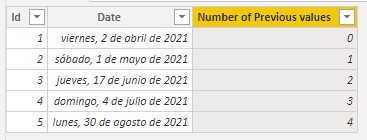
In this case, as the "previous" context is the only previous context, we could also use the EARLIEST function that returns the value of the field indicated in the last existing row context:
COALESCE(
COUNTROWS(
FILTER(
data,
data[Date] < EARLIEST(data[Date])
)
),
0
)
The second method is precisely by making use of variables, which is much simpler and easier to interpret. Specifically:
VAR __currentDate = data[Date]
RETURN
COUNTROWS(
FILTER(
data,
data[Date] < __currentDate
)
)
First we create a variable (__currentDate) with the VAR keyword. This variable will be created in the existing evaluation context which, at that point in the code, is the row context created by the calculated column. That is, at this point, the data[Date] field takes the value of the Date field in the row being evaluated.
Once the date has been registered, the filtering of the data table is executed. As mentioned, the FILTER function creates a new row context in which the table in question is iterated, comparing each value of the Date field -evaluated in the row context of the FILTER function- with the value registered in the variable __currentDate (value that was defined in the row context of the calculated column):
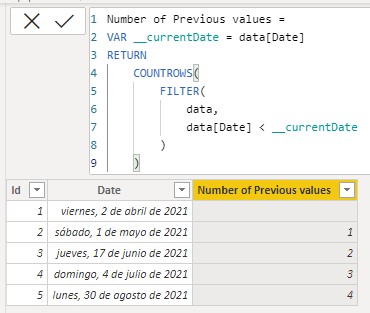
We can see that the result is the same as that obtained with the EARLIER function but easier to interpret.
Once again, we could use the COALESCE function to force zeros where COUNTROWS returns Blanks:
VAR __currentDate = data[Date]
RETURN
COALESCE(
COUNTROWS(
FILTER(
data,
data[Date] < __currentDate
)
),
0
)