En este sencillo escenario partimos de dos tablas:
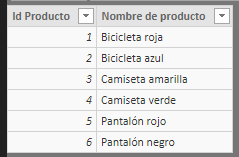
- Productos. Tabla de dimensiones conteniendo dos campos, con un identificador de cada producto y el nombre del producto. Vemos que hay 6 productos cuyos identificadores pertenecen al rango [1, 6]:
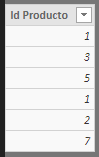
- Ventas: Tabla de hechos con una única columna conteniendo los identificadores de los productos vendidos. Podemos apreciar la existencia de una fila con el identificador 7 que no existe en la tabla de dimensiones anterior, lo que provoca una violación de integridad referencial:
Si creamos una tabla calculada con los identificadores de los productos vendidos y su nombre (extraído de la tabla producto), el resultado es el siguiente:
Productos vendidos = SELECTCOLUMNS(
Ventas;
"Id. Producto"; Ventas[Id Producto];
"Nombre"; RELATED(Productos[Nombre de producto])
)
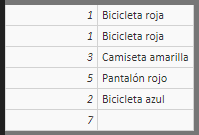
Para acceder a la columna "Nombre de producto" de la tabla "Productos" utilizamos la función RELATED que nos da acceso a una columna remota.
Vemos que el producto con identificador 7 no tiene un nombre asociado. Si quisiéramos contar el número de productos vendidos distintos y para ello utilizásemos la segunda columna de la tabla anterior (la que ha recibido el nombre de "Nombre"), podríamos hacerlo con dos funciones distintas: DISTINCTCOUNT y DISTINCTCOUNTNOBLANK. Si definimos dos medidas con estas funciones, tenemos lo siguiente (damos a las medidas el mismo nombre de la función usada en cada caso):
DISTINCTCOUNTNOBLANK = DISTINCTCOUNTNOBLANK('Productos vendidos'[Nombre])
DISTINCTCOUNT = DISTINCTCOUNT('Productos vendidos'[Nombre])
Si llevamos estas medidas a dos visualizaciones tipo tarjeta, tenemos:

Comprobamos que la función DISTINCTCOUNT cuenta el número de valores distintos considerando los valores vacíos (BLANK) como un valor adicional, mientras que DISTINCTCOUNTNOBLANK excluye estos valores vacíos.