X es, ya lo sabemos, un DataFrame Pandas. El objetivo de esta transformación es convertirlo en una lista en la que cada valor sea un array NumPy formado por las características predictivas de una muestra. Por poner un ejemplo, supongamos que el DataFrame X es el siguiente:
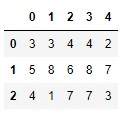
El objetivo es convertirlo en la siguiente lista:

Comprobamos que el primer valor de la lista es un array NumPy bidimensional de una única columna en el que los valores son los que encontrábamos en la primera fila del DataFrame. La conveniencia de esta transformación deberá quedar clara más adelante.
Pues bien, esta transformación puede ser realizada con el siguiente código:
x_train = [x.values.reshape(-1, 1) for (i, x) in X.iterrows()]
Vemos que recorremos cada fila de X con el método .iterrows() -extrayendo tanto el índice como la fila, aunque el índice no nos resulte de utilidad-, extraemos los valores de la fila con formato NumPy array usando el método .values() y, a continuación, lo redimensionamos de forma que tenga una única columna (y tantas filas como características predictivas).
Como vemos, el resultado se almacena en una variable a la que llamamos x_train.