DataFrame.rank(
axis=0,
method='average',
numeric_only=None,
na_option='keep',
ascending=True,
pct=False
)
The rank method of a pandas DataFrame returns another pandas DataFrame in which the values are the result of assigning ranges (from 1 to n) to the values of the original DataFrame, considering them ordered, by default, from lowest to highest along axis 0. That is, the smallest value in a column receives rank 1, the next rank 2, and so on. The method parameter controls the method of assigning ranges to matching values.
The index of the original DataFrame is preserved. The assigned ranges are real numbers.
- axis: (0 or "index" -default value-, 1 or "columns" ) Axis along which the ranges are calculated.
- method: ("average" -default value-, "min", "max", "first", "dense"). Criteria for assigning ranges to matching values. These criteria are based on the ranges that would be assigned to the group of values if each value received a different range (see examples below).
- "average": (Default value) returns the average value of the ranges that would be assigned to the group.
- "min": Minimum value of the group. The next value (outside the group) receives the rank assigned to the group + n, where n is the number of elements in the group.
- "max": Maximum value of the group.
- "first": Ranks assigned according to the order in which the values appear in the series.
- "dense": similar to "min" but the next value (outside the group) receives the rank assigned to the group + 1.
- na_option: ("keep" -default value-, "top", "bottom"). Control the handling of null values:
- "keep": Assign the NaN range to NaN values.
- "top": Assigns the lowest rank to the NaN values.
- "bottom": Assigns the highest rank to NaN values.
- ascending: (Boolean, True by default). If it takes the value True, the ranges will be assigned from lowest to highest value (the lowest value will receive the range 1.0).
- pct: (Boolean, False by default). Controls whether ranges will be displayed in fraction format.
The pandas.DataFrame.rank method returns a pandas DataFrame.
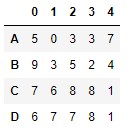
To test this method, let's generate a DataFrame made up of random numeric values:
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randint(0, 10, size = (4, 5)), index = list("ABCD"))
df
Now we execute the method with its default parameters:
df.rank()
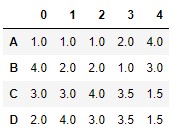
We note that, by default, the ranges have been assigned along the 0 axis (vertical axis). Column 1 was made up of increasing values (0, 3, 6, and 7), so the assigned ranges are 1.0, 2.0, 3.0, and 4.0, respectively.
In column 0 the smallest value is 5 (index "A" ), which receives the range 1.0. The next value -considering them from lowest to highest- is the number 6 (index "D" ) that receives the range 2.0.
In column 4 there are two values 1. If they received different ranges, being the lowest values, they would receive ranges 1.0 and 2.0 (or vice versa, it is indifferent), so they are shown in the result with the average value of said ranges (1.5).
We observe something similar in column 3, in which there are two values 8 (the highest) that would receive ranks 3 and 4 (if the assigned ranks were different), which is why they receive rank 3.5.
If, in the previous example, we wanted to modify the behavior for repeated values, we could do so by adding the method parameter. For example, we could assign the lowest rank (of which would be assigned if the ranks were different) with the following code:
df.rank(method = "min")
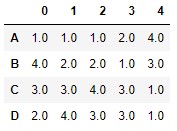
In this case, the two 1 values in column 4 have received a rank of 1.0 (which is the lowest of the 1.0 and 2.0 ranks that would be assigned if the ranks were different). We see, however, that no number has received the rank 2.0.
If we want the assignment of ranges to equal values to be determined by the parameter "min" but to be done without leaving gaps, we could achieve this by assigning the value "dense" to the method parameter:
df.rank(method = "dense")
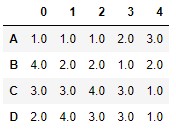
We see that the two 1 values in column 4 still receive the range 1.0, but the next assigned range is now 2.0.
The ascending parameter controls the way of assigning ranges: assuming the values ordered from lowest to highest (default value) or ordered from highest to lowest, which we can control in the following way:
df.rank(ascending = False)
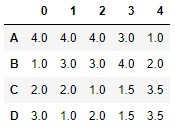
Now the 1.0 ranges are assigned to the highest values in each column.
If we wanted the ranges to be assigned along the horizontal axis, it would be enough to specify axis 1 (or "index") in the axes parameter:
df
df.rank(axis = 1)
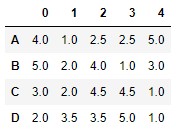
Now the row "A" that was made up of the values 5, 0, 3, 3, 7 receives the ranges 4.0, 1.0, 2.5, 2.5 and 5.0. The number 0 -the smallest of all- is the one that has received the rank 1.0. The 3 values that appear twice are given the range 2.5 (mean of 2.0 and 3.0).
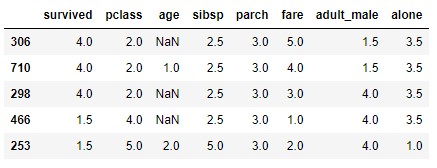
This method does not only apply to numeric values. Let's load in the variable df 5 random records extracted from the titanic dataset that we can download from the seaborn library:
import seaborn as sns
titanic = sns.load_dataset("titanic").sample(5)
titanic

If we now apply the rank method we see that all columns receive ranks:
titanic.rank()
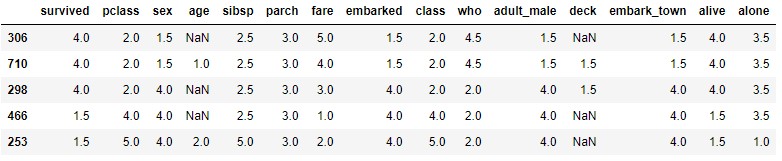
We can select only the numeric columns with the numeric_only parameter:
titanic.rank(numeric_only = True)