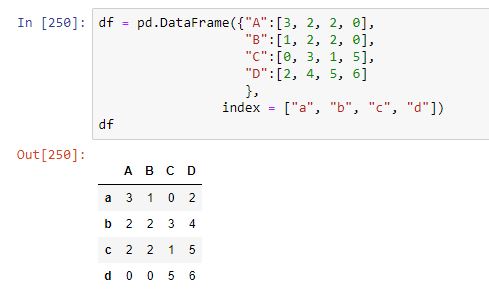
El método pandas.DataFrame.sort_values asociado a todo dataframe es el que nos va a permitir ordenarlo según sus valores. En el caso de una estructura de dos dimensiones, hay dos elementos que van a definir cómo realizar la ordenación: el eje escogido (eje 0, por defecto) y, dentro de ese eje, qué fila o columna (o qué filas o columnas) van a determinar el orden de los datos. Para ver algunos ejemplos, partamos del siguiente dataframe:
Supongamos que queremos ordenar esta estructura según la columna A, es decir, según el eje vertical o eje 0:
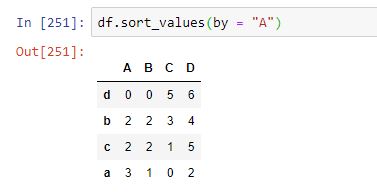
Al tratarse del eje por defecto, no ha sido necesario especificarlo mediante el parámetro axis. Las columnas (en este caso solo una) que determinan el criterio de ordenación se han indicado mediante el parámetro by (si se trata de una única fila o columna basta indicar el nombre de la misma. Si se tratase de más de una, habría que agregarlas en forma de lista). Por cierto, este método exige trabajar con etiquetas, no acepta índices.
Las filas se han reordenado de forma que la columna A muestre sus valores ordenados de menor a mayor. Las filas cuyas etiquetas son "b" y "c" , al tener el mismo valor en la columna "A", reciben una ordenadión por defecto (la que imponga el código que, probablemente, deja el mismo orden en el que aparecen en el dataframe original). Si quisiéramos ordenar las filas también según una segunda columna, podríamos hacerlo fácilmente:
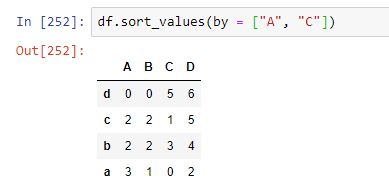
Las filas "b" y "c", que en el ejemplo anterior no se ordenaban entre sí pues no había criterio alguno que lo impusiese, ahora sí se muestran ordenadas según la columna "C".
Si deseásemos ordenar el dataframe según los valores de las filas "a" y "b", por ejemplo, y de mayor a menor, podríamos conseguirlo del siguiente modo:
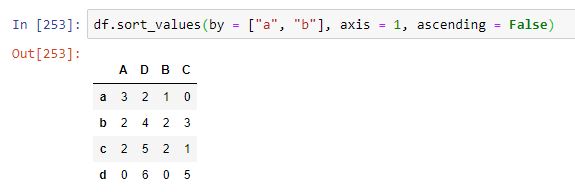
En este caso ha sido necesario especificar el eje de ordenación, al no tratarse del eje por defecto (argumento axis = 1).