DataFrame.drop(
labels = None,
axis = 0,
index = None,
columns = None,
level = None,
inplace = False,
errors = 'raise'
)
The .drop() method associated with a pandas dataframe returns a copy of it after deleting the indicated rows or columns. These should be referenced by their explicit labels, not by their position on the axis.
The deletion is done, by default, on the vertical axis (rows are deleted, therefore).
- labels: Label or list of labels to delete.
- axis: Axis in which to carry out the elimination. You can enter the value 0 or "index" to refer to axis 0 (and eliminate rows), or the value 1 or "columns" to refer to axis 1 (and eliminate columns). The default value is 0.
- index: Label or list of labels to remove from axis 0.
- columns: Label or list of labels to remove from axis 1.
- level: Integer number or name of the level to remove from a multilevel index.
- inplace: Boolean. If it takes the value True, the elimination is performed on the same dataframe. If set to False, the method returns a copy of the dataframe after removing the specified rows or columns.
- errors: This parameter can take the values "ignore" or "raise" and is considered when any of the referenced labels does not exist. The default value is "raise" which causes the function to return an error when any label does not exist. If the value of this parameter is set to "ignore", errors are ignored.
The index and columns parameters are alternatives to the axis parameter. Only one parameter can be specified from axis, index and columns.
The result is a pandas dataframe regardless of the number of rows or columns that are removed.
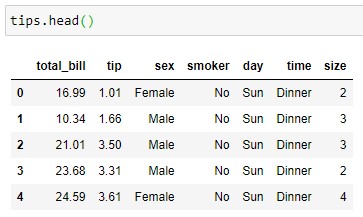
We start from the dataframe tips provided by seaborn:
tips.head()
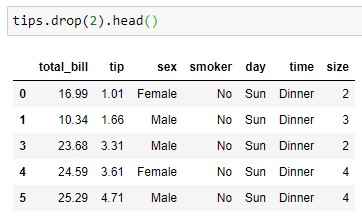
By default, rows are deleted and a copy of the dataframe is returned after deleting:
tips.drop(2).head()
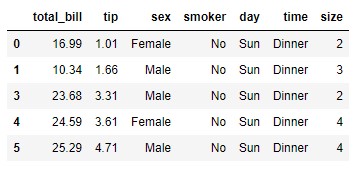
We get the same result if we specify the "index" parameter:
tips.drop(index = 2).head()
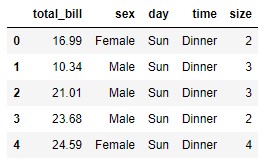
It is possible to simultaneously delete more than one row or column passing as an argument not a label but a list of them:
tips.drop(columns = ["tip", "smoker"]).head()
If any of the indicated labels does not exist, the method returns an error:
try:
tips.drop(columns = ["tip", "smoker", "weather"]).head()
except:
print("Error")
Error
However, we can force the function to ignore these non-existent tags by setting the errors parameter to "ignore":
tips.drop(columns = ["tip", "smoker", "weather"], errors = "ignore").head()
The result is a dataframe even if all rows or all columns are removed:
df = tips.drop(tips.columns, axis = 1)
df

type(df)
pandas.core.frame.DataFrame
Multi-indexes
To test the behavior of this function with multi-indexes we start from the following dataframe:
data = tips.pivot_table(index = ["sex", "time"])
data
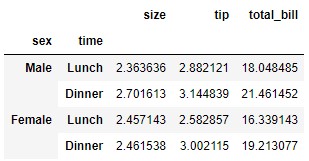
If we want to remove, for example, the "Male" tag from the index (tag found at level 0 of the multi-index), we can achieve it with the following code:
data.drop(index = ["Male"], level = 0)
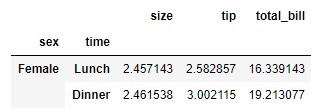
We can obtain the same result by referring not to the level, but to its name:
data.drop(index = ["Male"], level = "sex")
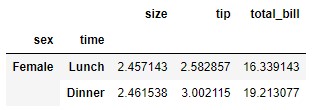
The function allows us to remove labels from "higher" levels. For example:
data.drop(index = ["Lunch"], level = "time")
