Tal y como se ha comentado, estamos implementando un clasificador (para aplicarlo, por ejemplo, al dataset MNIST). Esto significa que la última de las capas (la capa de salida) tendrá tantas neuronas como categorías tengamos identificadas en nuestro dataset de entrenamiento. En el caso del MNIST esto quiere decir que cuando pasemos a la red los valores de una imagen tendremos 10 valores de salida, cada uno representando el grado de confianza que la red tiene en que dicha imagen represente al número correspondiente a la neurona en cuestión.
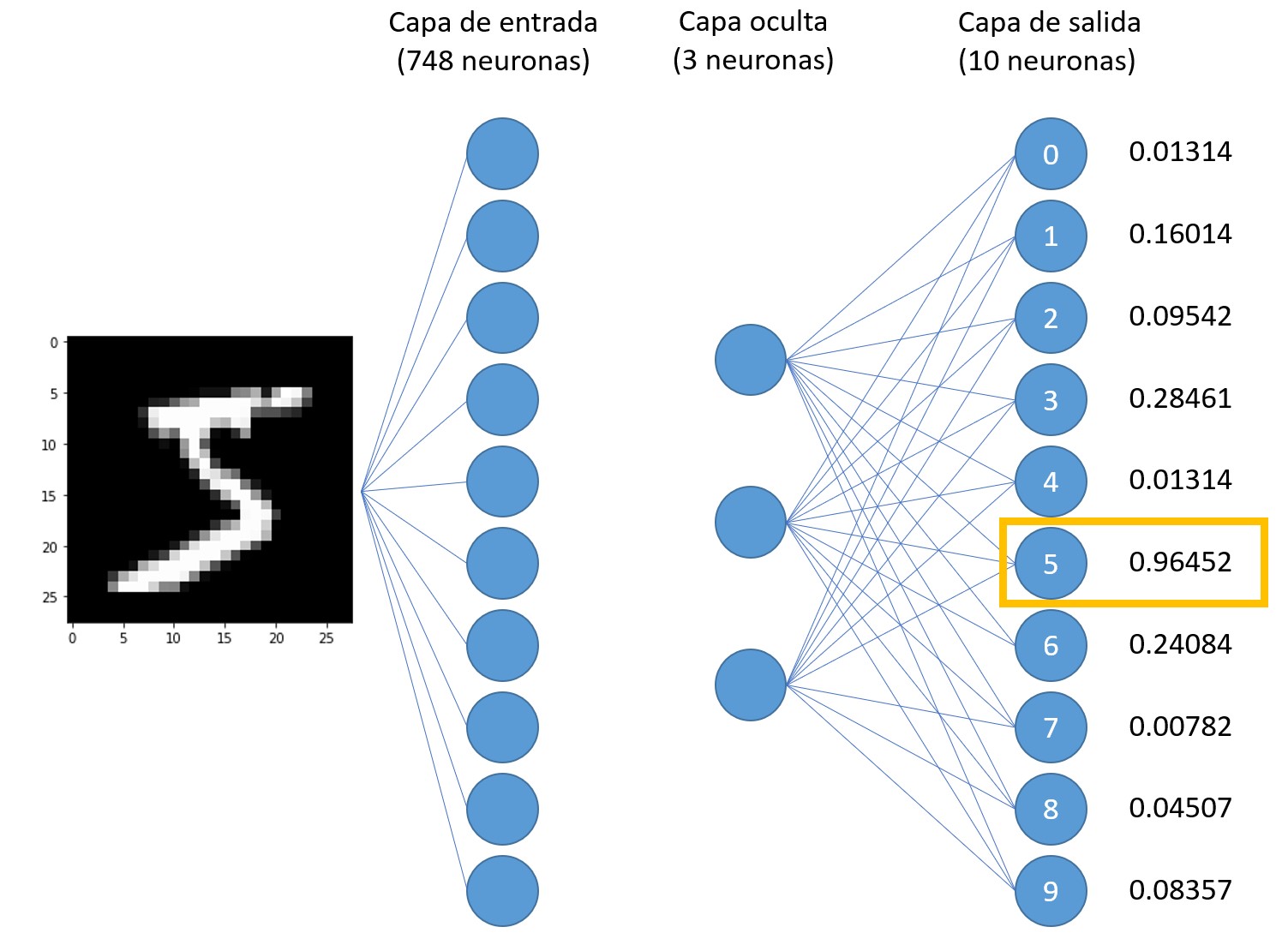
En este ejemplo se supone que estamos pasando a la red los 28x28 valores que forman la imagen (solo se muestran 10 de las 748 neuronas), que tenemos una única capa oculta con tres neuronas (no se muestran los enlaces que las unen a las neuronas de la capa de entrada) y 10 neuronas en la capa de salida. Si la imagen de entrada representa un "5" y la red está correctamente configurada, el valor más elevado de los obtenidos en la capa de salida será el correspondiente a la neurona que ocupa el índice o posición 6 (si comenzamos a contar neuronas a partir del número 0). Vemos, por ejemplo, que la red ha asignado el valor 0.01314 a la posibilidad de que la imagen de entrada represente un cero y comprobamos que, efectivamente, el valor más elevado es el correspondiente al número 5 (la sexta neurona): 0.9645.
Todo esto supone también que cuando entrenemos la red, deberemos hacerlo indicándole a ésta los valores que componen la imagen y la variable objetivo, que será el número representado por la imagen. En el ejemplo de la imagen anterior deberemos pasar a la red los 748 valores que definen la imagen (características predictivas) y el número 5 (variable objetivo). Pero lo que necesitará la red no es el valor "5": necesitará 10 valores, uno para cada una de las 10 neuronas de salida, valores que tomarán el valor 0 salvo el correspondiente al valor que ocupe el índice que nos interese, que deberá tomar el valor 1.
En el caso concreto del 5, será necesario transformar este número en el vector [0, 0, 0, 0, 0, 1, 0, 0, 0, 0], que será el vector que querremos que la red nos devuelva cuando le pasemos los 748 píxels de nuestro cinco.
Esta conversión podemos realizarla nosotros durante la preparación de los datos de entrenamiento, o puede realizarla la red neuronal. En nuestra implementación, será la red la que lo realice.