Veamos entonces cuáles serían las fronteras de decisión de nuestro clasificador “model” entrenado sobre el dataset Iris:
ax.set_aspect("equal")
plot_decision_boundaries(model, X.values, ax)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.4)
plt.show()
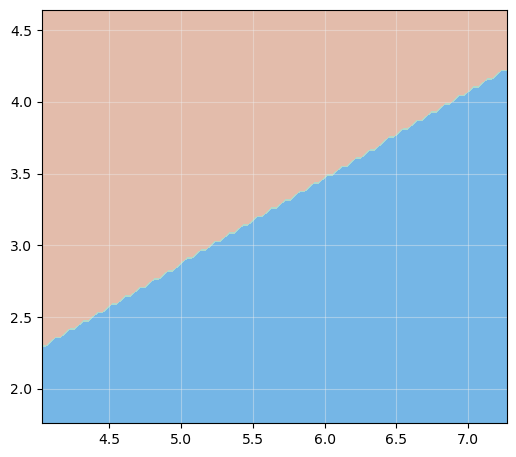
Tal y como cabía esperar, la frontera de decisión es una línea recta.
Más interesante resulta si mostramos los datos de entrenamiento encima:
fig, ax = plt.subplots(figsize = (6, 6))
ax.set_aspect("equal")
plot_decision_boundaries(model, X.values, ax)
scatter = plt.scatter(
x = X["sepal_length"], y = X["sepal_width"], c = iris.label,
cmap = colors, zorder = 2, edgecolor = "#666666")
ax.legend(
handles = scatter.legend_elements()[0],
labels = list(iris.species.unique())
)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.4)
plt.show()
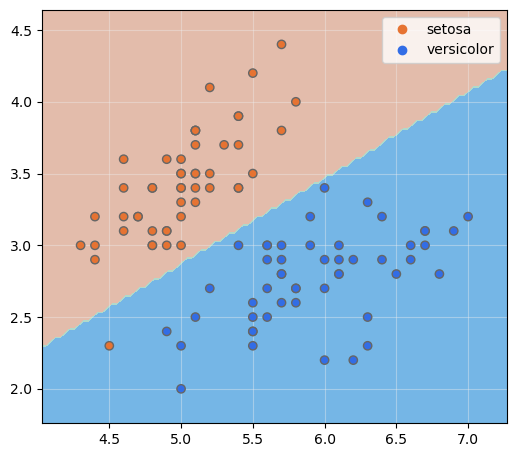
Comprobamos que el entrenamiento ha terminado antes de que el algoritmo haya convergido en una recta que divida de forma perfecta los datos. Si queremos comprobar el porcentaje de muestras bien clasificadas, no tenemos más que pasar al método .score() del modelo los propios datos de entrenamiento:
que nos devuelve un 99%. Es decir, ha quedado una muestra mal clasificada, tal y como se ve en la imagen anterior.
Podemos visualizar el número de epochs durante las cuales se ha entrenado el modelo con el atributo .n_iter_:
Comprobamos que los datos han pasado 8 veces por la neurona antes de que el algoritmo haya parado el entrenamiento.