La teoría que hay detrás del descenso de gradiente parece clara. Ahora ¿cómo se aplicaría a una red neuronal? Recordemos el esquema de nuestra red:
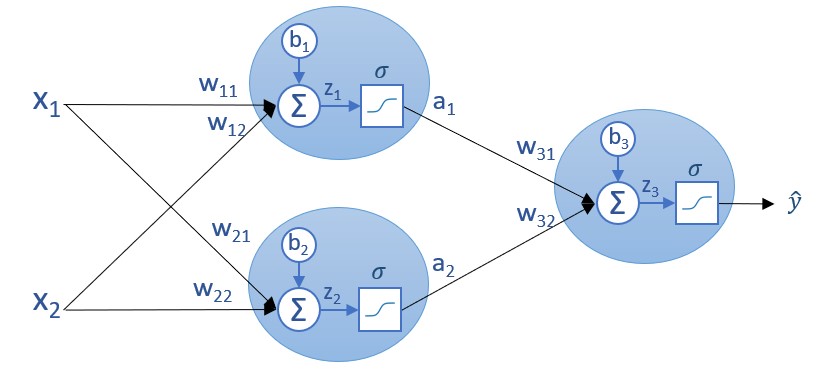
Según hemos visto, la función de error, C, depende de todos los parámetros de la red. En este caso:
C = C(w11, w12, b1, w21, w22, b2, w31, w32, b3)
El objetivo, por lo tanto, es calcular la derivada parcial de C con respecto a todos los parámetros, lo que no parece sencillo considerando la función que vimos que liga a C con dichos parámetros:
C = ?(σ(w31*σ(w11*x1i + w12*x2i + b1) + w32*σ(w21*x1i + w22*x2i + b2) + b3) - yi)2
(y recordemos una vez más que el ejemplo en el que estamos trabajando es extremadamente simple)