La matriz de valores de entrada, a la que hemos llamado x, deberá ser una matriz formada por una única columna con los valores devueltos por la capa anterior (sea la capa de entrada o una capa oculta):
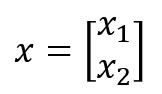
Si la capa anterior era la capa de entrada, nuestra matriz x tendrá tantas filas como características predictivas tenga nuestro dataset.
Si, por el contrario, la capa anterior era una capa oculta, nuestra matriz x tendrá tantas filas como neuronas tuviese dicha capa.