Al tratarse de un dataset con cuatro características predictivas (lo que podemos considerar un dataset conteniendo muestras en un espacio de cuatro dimensiones), no resulta posible visualizarlo considerándolas todas (podríamos aplicar un algoritmo de reducción de dimensionalidad, pero estaríamos modificando los datos de los que partimos), de forma que, si queremos inspeccionar visualmente los datos en una gráfica, tendremos que limitarnos a considerar dos o tres características predictivas simultáneamente.
Por ejemplo, podríamos visualizar la relación que hay entre la longitud y el ancho de los sépalos llevando ambas características a un diagrama de dispersión:
ax.set_aspect("equal")
scatter = ax.scatter(
x = iris["sepal_length"], y = iris["sepal_width"],
c = iris.label, zorder = 2, edgecolor = "#999999",
cmap = ListedColormap(["#E67332", "#FADB15", "#4193E5"])
)
ax.set_title("Sepal length vs. Sepal width")
ax.set_xlabel("Sepal length (cm)")
ax.set_ylabel("Sepal width (cm)")
ax.legend(
handles = scatter.legend_elements()[0],
labels = list(iris.species.unique())
)
ax.grid(color = "#EEEEEE", zorder = 1, alpha = 0.9)
plt.show()
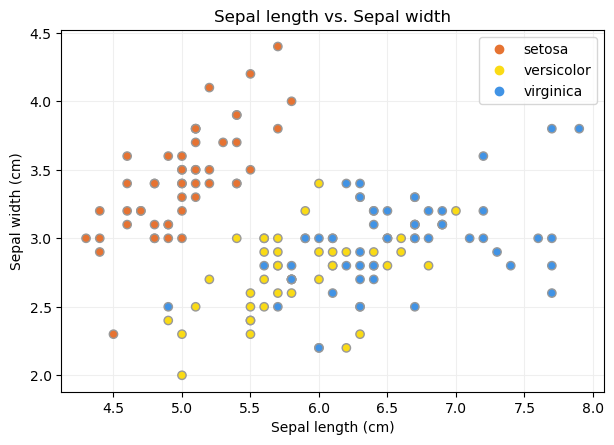
Comprobamos que, considerando estas dos características, solamente la especie setosa es linealmente separable de las otras dos.