Cuando hablamos de algoritmos de Machine Learning estamos hablando de un tipo especial de algoritmo, de esos que permiten a un ordenador aprender a realizar una actividad de forma autónoma. En el ejemplo de la aseguradora de coches se ha hecho referencia implícita a un algoritmo que se denomina "árbol de decisión" que va construyendo una estructura con forma de árbol en la que, en cada nodo, se plantea una pregunta del tipo "¿tiene el coche más de 10 años?" o "¿el conductor es mujer?". Una vez que el algoritmo ha recorrido todos los datos conocidos con información de tomadores antiguos del seguro llegaría a una estructura del siguiente tipo:
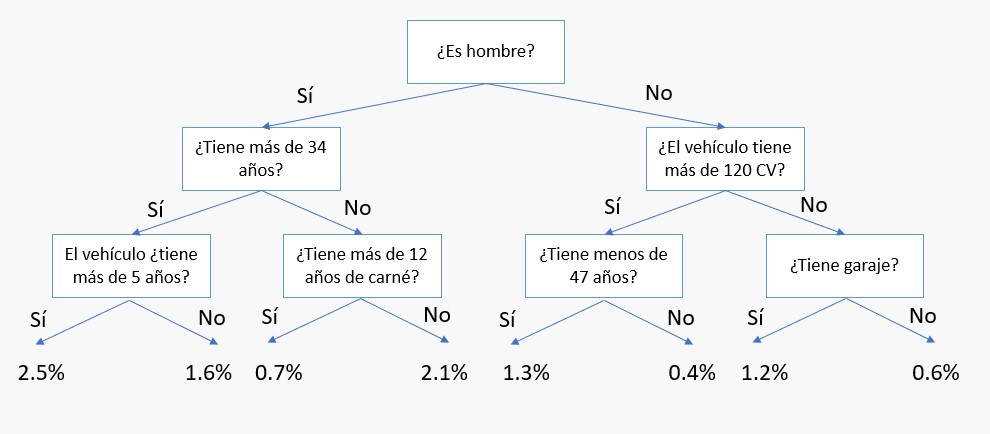
Ahora, si llegase a nosotros un nuevo cliente queriendo contratar un seguro de coche, para comprobar su probabilidad de accidente bastaría con recorrer el árbol de arriba abajo respondiendo las preguntas hasta llegar al final, donde encontramos –en este ejemplo- la probabilidad de accidente asignada al grupo de conductores caracterizados por las respuestas dadas. Así, por ejemplo, si llegase a nosotros un nuevo cliente, hombre, de 45 años, con un vehículo de 10 años de antigüedad, llegaríamos a la conclusión de que la probabilidad de accidente asignada por nuestro árbol de decisión es del 2.5% (las cifras mostradas en el árbol son imaginarias).
La cuestión de cómo el algoritmo escoge las preguntas para crear el árbol queda para otra sección de este tutorial. Lo que nos importa es que, de alguna forma, el algoritmo ha construido este árbol de decisión y que, al menos aplicado a los tomadores conocidos, devuelve el mejor resultado que el algoritmo ha sido capaz de obtener. El reto en este escenario es que, aplicado a nuevos clientes, sea también capaz de predecir su probabilidad de accidente.