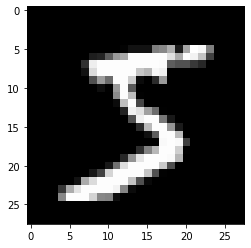Vamos a leer el dataset y almacenarlo en un DataFrame pandas y a mostrar el primero de los dígitos usando matplotlib. Comenzamos importando ambas librerías:
import pandas as pd
import matplotlib.pyplot as plt
A continuación, leemos el fichero (en este caso lo suponemos ya descomprimido) y mostramos la cabecera del DataFrame:
data = pd.read_csv("mnist.csv", header = None)
data.head()
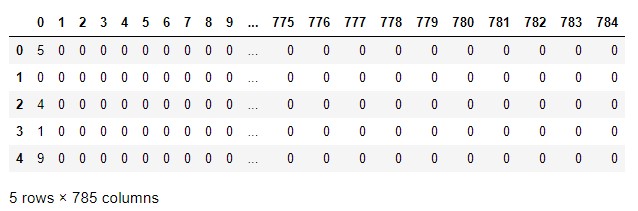
Como podemos ver, el fichero CSV no contiene cabeceras de columnas. Confirmemos el número de muestras y de columnas que incluye:
data.shape
(60000, 785)
Hay 60.000 muestras. El número de columnas es de (28 x 28) + 1 = 785. Concretamente la primera columna (la columna de índice 0) contiene la etiqueta de cada muestra (el número representado en la imagen) y las 784 restantes contienen los píxels de la imagen, habiéndose registrado éstos de izquierda a derecha y de arriba abajo:
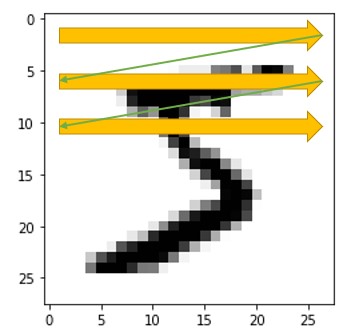
Es decir, la columna de índice 1 contiene el píxel de la esquina superior izquierda de cada imagen. La columna de índice 28 contiene el píxel de la esquina superior derecha, y la columna de índice 29 contiene el píxel izquierdo de la segunda fila de la imagen.
Ahora llevamos a las variables X e y las características predictivas y la etiqueta, respectivamente:
y = data.pop(0)
X = data
Por último, mostramos en pantalla el primer dígito, que contiene un "5":
y[0]
5
plt.imshow(X.iloc[0, :].values.reshape(28, 28), cmap = "binary_r");