El hecho de que los dígitos manuscritos hayan sido redimensionados de forma que su tamaño sea semejante y que se hayan girado y centrado en el grid de 28x28 píxels hace de este dataset un conjunto de datos que podemos calificar de "sencillo" y abordable con relativo éxito aplicando diferentes algoritmos de Machine Learning.
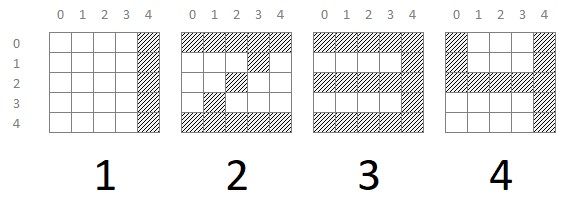
Para entender la "bondad" de este dataset vamos a simplificarlo todavía más para mostrar más evidentemente sus características. Supongamos que las imágenes fuesen grids de 5x5 píxels y que visualizamos cuatro de ellas, representando los números 1, 2, 3 y 4: