Realicemos un ejercicio adicional: Vamos a extraer solo dos componentes principales del dataset Wine. A continuación, entrenaremos un modelo de regresión logística a partir de ambas características predictivas y mostraremos las fronteras de decisión del modelo. Comenzamos extrayendo los dos componentes principales:
pca = PCA(n_components = 2)
X_pca = pca.fit_transform(X_scaled)
X_pca = pca.fit_transform(X_scaled)
Aplicamos el método de retención para dividir el dataset:
X_train, X_test, y_train, y_test = train_test_split(X_pca, y)
Y entrenamos el modelo:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
model.fit(X_train, y_train)
Ahora podemos mostrar las fronteras de decisión:
class_names = ["Clase " + str(n) for n in y.unique()]
show_boundaries(model, X_train, X_test, y_train, y_test, class_names)
show_boundaries(model, X_train, X_test, y_train, y_test, class_names)
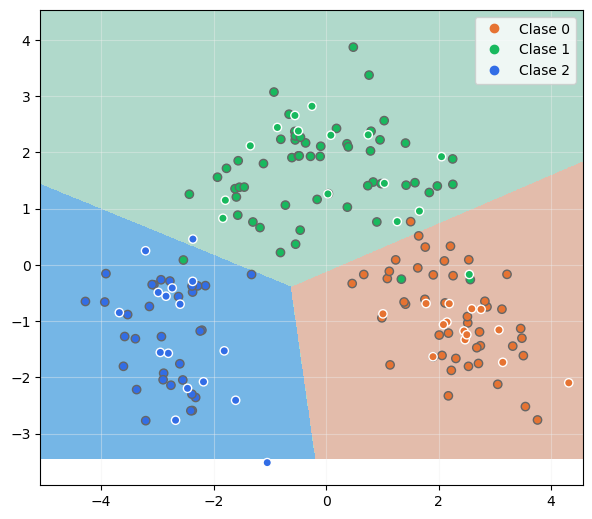
Podemos ver que los dos componentes principales extraídos permiten la clasificación de las tres clases con pocos errores.