El número de vecinos a escoger, k, va a depender, en todo caso, de los datos de los que dispongamos. En general, un valor bajo de k hará que el resultado de la predicción se ajuste mucho a los datos de entrenamiento (con el peligro conocido de caer en sobreentrenamiento) y hará depender la predicción de factores como el ruido que pueda existir en los datos, mientras que un valor de k elevado derivará en una predicción con pocos cambios de un punto a otro (poca varianza), lo que podemos interpretar como subentrenamiento. En un caso extremo, si el valor de k coincidiese con el número de muestras en el conjunto de entrenamiento, fuese cual fuese el punto a clasificar, siempre consideraríamos como vecinos a todos los puntos disponibles, con lo que la predicción sería siempre la de la clase mayoritaria.
Para ver el efecto de la elección del valor de k podemos visualizar las fronteras de decisión para diferentes valores entrenando el modelo a partir de las características "sepal_length" y "sepal_width" del dataset Iris:
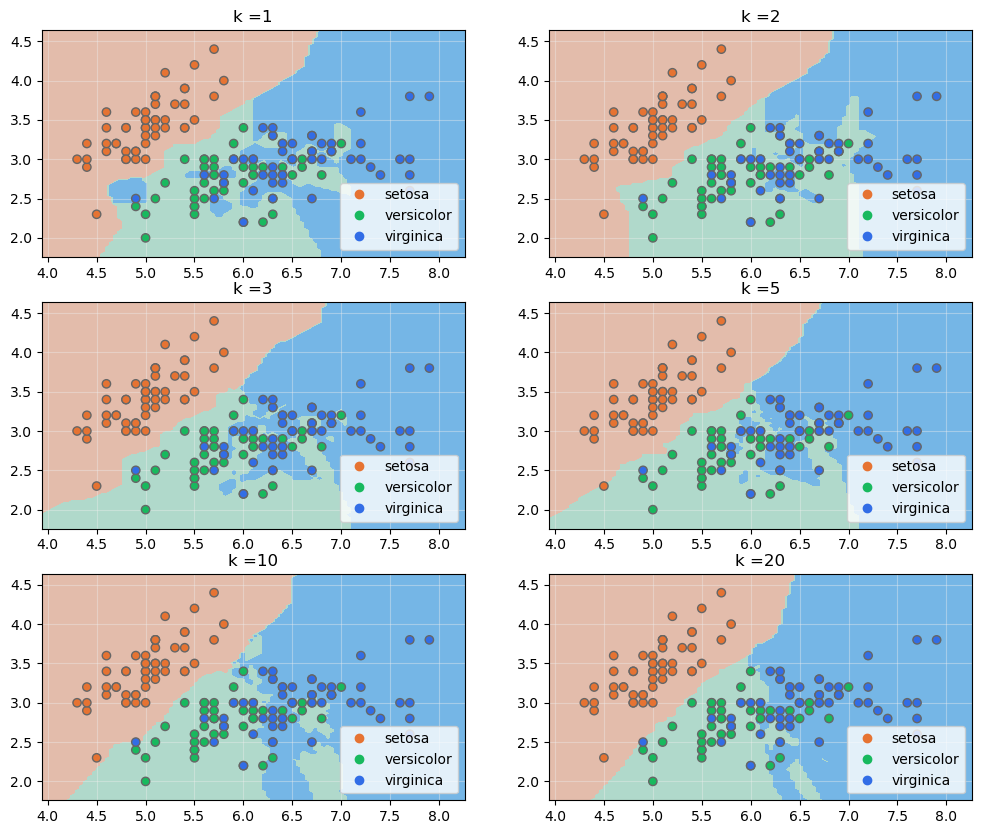
Podemos comprobar cómo, para k igual a 1, todos los puntos tienen un área alrededor a la que se asignaría su clase, haciendo los límites entre áreas más abruptos. En este caso, la predicción tiende a ajustarse mucho al perfil de los datos de entrenamiento, con el riesgo de sobreentrenamiento comentado. A medida que aumenta k tienden a desaparecer esas "islas", aunque aparecen otras, debido a empates en las votaciones. Salvo este detalle, los límites de las áreas se hacen más suaves, ajustándose cada vez menos a los datos de entrenamiento, pudiendo caer en el subentrenamiento, tal y como se ha comentado.