Veamos con un poco más de detalle cómo se realizaría la predicción de la clase a asignar a una muestra. Supongamos, por ejemplo, que tenemos los siguientes puntos definidos por dos características x e y que definen nuestro conjunto de entrenamiento:
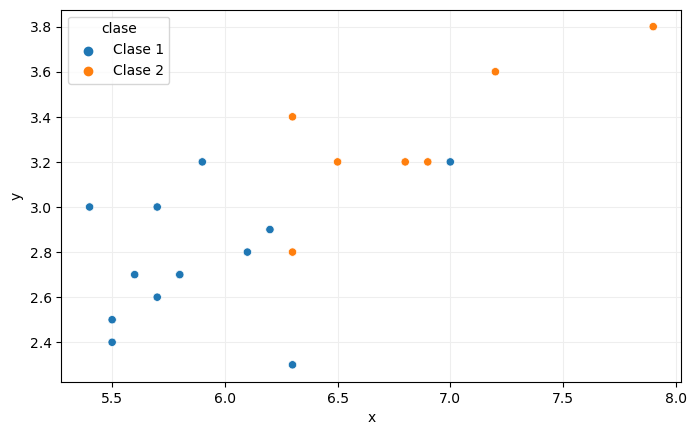
Los puntos están clasificados en dos clases: clase 1 y clase 2, distinguibles en la imagen por su color. Supongamos ahora que tenemos dos puntos adicionales, A y B, cuya clase no conocemos:
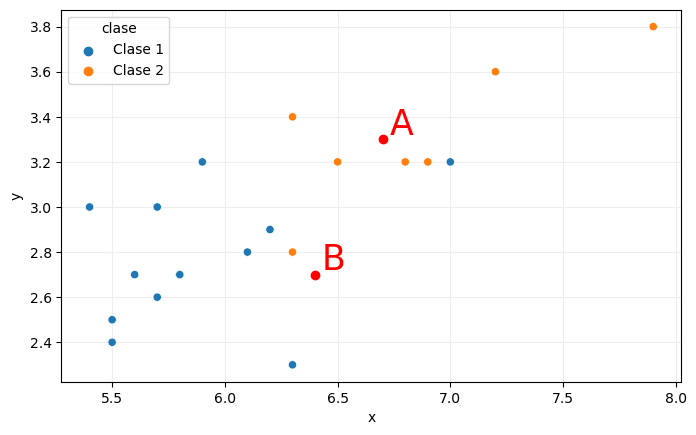
Para aplicar el algoritmo k-NN y predecir la clase de estos dos puntos tendríamos que considerar los k puntos más próximos a ellos. Comencemos con k igual a 1, por ejemplo:
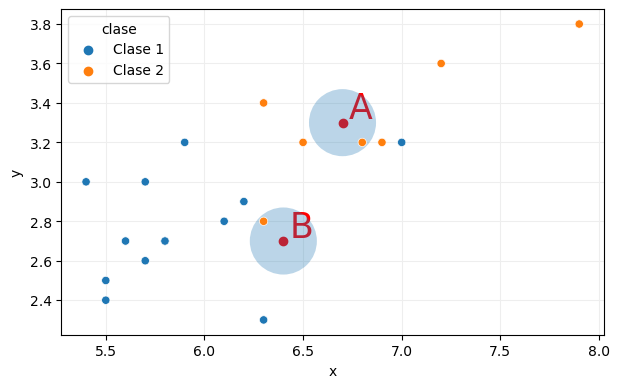
El punto del conjunto de entrenamiento más próximo al punto A es un punto de la clase 2 (naranja), por lo que el punto A recibiría como predicción esa clase. De forma semejante, el vecino más próximo al punto B es también de la clase 2, por lo que B recibiría como predicción la clase 2.
El considerar solo un punto supone un cierto riesgo, ya que el ruido podría determinar una predicción errónea. Un método más conservador es considerar no un único vecino, sino varios, y establecer el resultado por "votación" (escogiendo la predicción mayoritaria). Repitamos el proceso con tres vecinos:
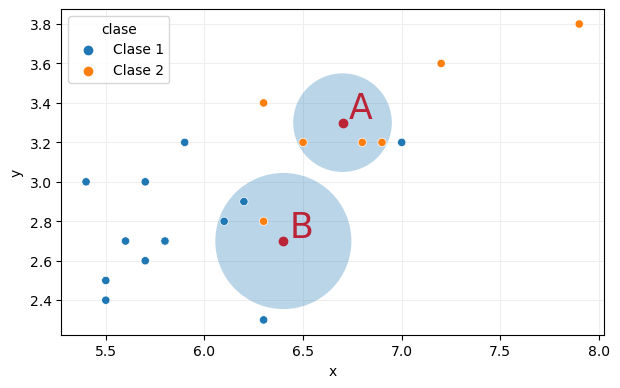
La predicción para el punto A no cambia, pues los tres vecinos más próximos son de la clase 2, por lo que A sigue recibiendo como predicción esta clase. Pero obsérvese como ahora la predicción para B ha cambiado, pues, de los tres vecinos, dos son de la clase 1 y solo uno de la clase 2, por lo que el resultado de la "votación" asignaría al punto B la clase 1.
En el caso de que exista un empate, la implementación de Scikit-Learn devuelve como predicción la clase de la muestra más próxima a aquellas para la que estamos realizando la predicción.