Apliquemos este algoritmo al dataset Iris. Como queremos mostrar las fronteras de decisión, seleccionamos apenas dos características predictivas: sepal_length y sepal_width. Cargamos los datos:
iris = sns.load_dataset("Iris")
iris["label"] = iris.species.astype("category").cat.codes
iris["label"] = iris.species.astype("category").cat.codes
X = iris[["sepal_length", "sepal_width"]]
y = iris.label
y = iris.label
Creamos los bloques de entrenamiento y validación:
X_train, X_test, y_train, y_test = train_test_split(X, y)
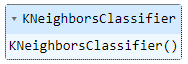
Importamos el algoritmo, lo instanciamos con sus parámetros por defecto y lo entrenamos:
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(X_train.values, y_train)
model.fit(X_train.values, y_train)
Comprobemos, en primer lugar, el porcentaje de aciertos en el dataset de validación:
model.score(X_test.values, y_test)
0.7368421052631579
No es muy elevado, pero recordemos que estamos considerando solo dos características predictivas.
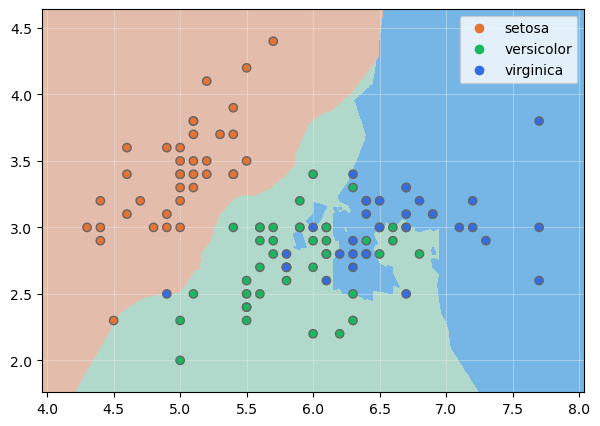
Visualicemos la frontera de decisión:
show_boundaries(model, X_train.values, None, y_train, None, iris.species.unique())