El sobreentrenamiento del modelo es un problema común en el aprendizaje automático, donde un modelo se entrena de forma que funciona correctamente aplicado a un conjunto de datos de entrenamiento específico, pero funciona mal con datos no conocidos. Esto ocurre cuando el modelo es demasiado complejo y ha aprendido el ruido en los datos de entrenamiento en lugar de la relación subyacente.
El sobreentrenamiento puede llevar a la incapacidad de generalizar el resultado del modelo predictivo y, por tanto, a un mal rendimiento trabajando con nuevos datos. Es importante evitar el sobreentrenamiento para construir un modelo robusto y preciso.
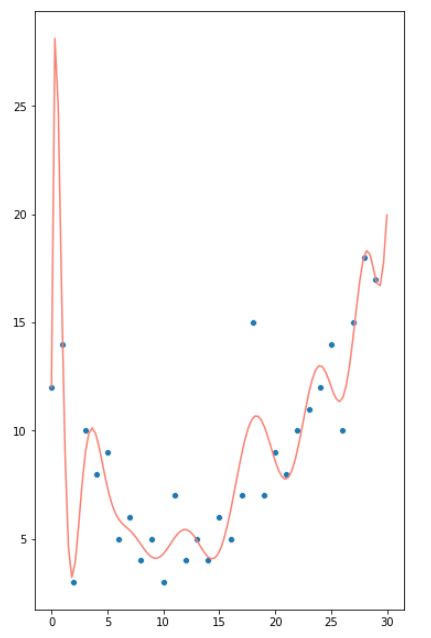 Hay varias formas de evitar el sobreentrenamiento:
Hay varias formas de evitar el sobreentrenamiento:
-
Usar un modelo más simple: Un modelo con menos parámetros es menos propenso a sobreentrenar los datos. Al usar un modelo más simple, podemos reducir el riesgo de sobreentrenamiento y mejorar la capacidad de generalización del modelo.
-
Usar validación cruzada: La validación cruzada (o cross-validation) es una técnica que implica dividir el conjunto de datos de entrenamiento en diferentes bloques y entrenar el modelo en diferentes combinaciones de estos bloques. Esto nos permite evaluar el rendimiento del modelo en datos no vistos e identificar si está sobreentrenado.
-
Usar regularización: La regularización es una técnica que impone restricciones al modelo para evitar que se sobreentrene. Esto se puede hacer añadiendo un término de penalización a la función de pérdida durante el entrenamiento.
-
Usar más datos: Cuanto más datos tengamos, menos probabilidades hay de que nuestro modelo se sobreentrene. Al aumentar el tamaño del conjunto de datos de entrenamiento, podemos reducir el riesgo de sobreentrenamiento y mejorar la capacidad de generalización del modelo.
-
Aplicar early stopping: early stopping es una técnica que implica interrumpir el proceso de entrenamiento cuando el rendimiento del modelo en el conjunto de datos de validación comienza a deteriorarse. Esto puede ayudar a evitar el sobreentrenamiento al evitar que el modelo aprenda el ruido contenido en los datos de entrenamiento.
Siguiendo estas técnicas, podemos evitar el sobreentrenamiento y construir un modelo robusto y preciso. Es importante tener en cuenta que el sobreentrenamiento puede ocurrir en cualquier etapa del proceso de aprendizaje automático y es importante estar atentos para evitarlo.