Los árboles de decisión son un algoritmo de aprendizaje automático popular que se utiliza tanto para tareas de clasificación como de regresión. Son un tipo de algoritmo de aprendizaje supervisado que se pueden utilizar para predecir una variable objetivo en base a una o más variables de entrada.
La estructura básica de un árbol de decisión es un gráfico de tipo árbol, con cada nodo interno representando una decisión o prueba sobre una variable de entrada, y cada nodo hoja representando una predicción o etiqueta de clase. El algoritmo funciona recursivamente dividiendo el espacio de entrada en regiones más pequeñas, llamadas ramas, en base a los valores de las variables de entrada. La partición se realiza de tal manera que cada rama corresponde a un valor específico o rango de valores para las variables de entrada, y el objetivo es maximizar la separación entre las diferentes clases o valores objetivos.
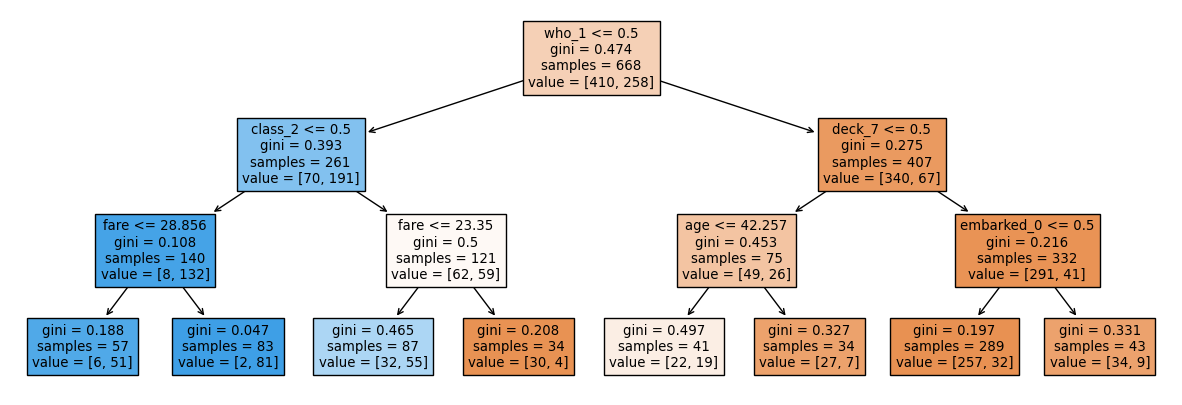
Una de las principales ventajas de los árboles de decisión es que son fáciles de interpretar y entender. La estructura de árbol proporciona una representación visual clara de las decisiones y la lógica utilizadas para hacer predicciones, lo que facilita a los humanos entender el razonamiento detrás de una predicción. Además, los árboles de decisión son relativamente fáciles de implementar y se pueden aplicar a una amplia gama de problemas, lo que los convierte en una opción popular para muchas tareas de aprendizaje automático.
Algunas aplicaciones comunes de los árboles de decisión incluyen:
- Tareas de clasificación como la identificación de correo electrónico no deseado o transacciones de tarjetas de crédito fraudulentas
- Tareas de regresión como la predicción de precios de acciones o precios de casas
- Diagnóstico médico y planificación de tratamientos
- Reconocimiento de imágenes y voz
- Procesamiento del lenguaje natural
Existen diferentes algoritmos para construir árboles de decisión. Algunos populares incluyen ID3, C4.5, C5.0 y CART. Cada algoritmo tiene sus propias fortalezas y debilidades, y la elección de qué algoritmo utilizar depende de la aplicación específica y del tipo de datos que se estén analizando.