La validación cruzada es un método estadístico utilizado para evaluar el rendimiento de los modelos de aprendizaje automático. Es una técnica que se utiliza para validar la capacidad del modelo para generalizar a nuevos datos, y es especialmente útil cuando el modelo tiene pocos puntos de datos o cuando los datos están desequilibrados.
Existen varios tipos de métodos de validación cruzada, incluyendo:
-
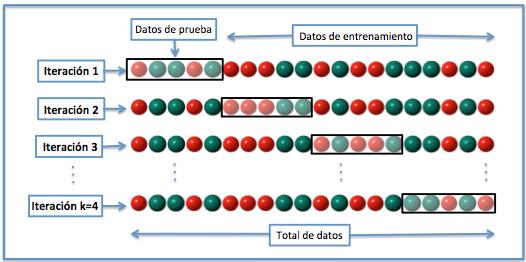
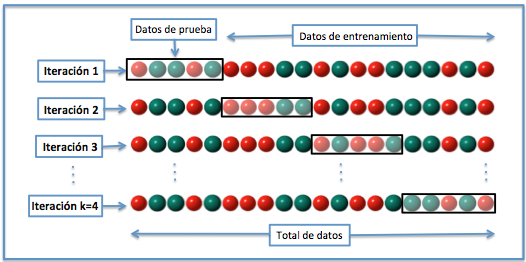
Validación cruzada K-fold: Este método implica dividir los datos en k folds, donde k-1 folds se utilizan para el entrenamiento y un fold se utiliza para la prueba. El proceso se repite k veces, con un fold diferente utilizado como el conjunto de prueba cada vez. El rendimiento promedio en todas las k iteraciones se utiliza para evaluar el modelo.
-
Validación cruzada K-fold estratificada: Este método es similar a la validación cruzada K-fold, pero asegura que la distribución de clases en los folds es la misma que la distribución en el conjunto de datos en su totalidad. Esto es especialmente importante cuando los datos están desequilibrados, ya que asegura que el modelo se pruebe en un subconjunto representativo de los datos.
-
Validación cruzada leave-one-out: Este método implica entrenar el modelo en todos los datos excepto en uno, y luego utilizar ese único dato como conjunto de prueba. Este proceso se repite para cada punto de datos, lo que resulta en un gran número de iteraciones. Es computacionalmente intensivo, pero proporciona una evaluación muy exhaustiva del modelo.
-
Validación cruzada K-fold repetida: Este método implica repetir el proceso de validación cruzada K-fold un número de veces, con diferentes divisiones aleatorias de los datos cada vez. El rendimiento promedio en todas las iteraciones se utiliza para evaluar el modelo.
La validación cruzada es un paso importante en el proceso de aprendizaje automático, ya que ayuda a garantizar que el modelo sea robusto y capaz de generalizar a nuevos datos. Es especialmente útil cuando los datos son limitados o desequilibrados, ya que permite que el modelo sea probado en un subconjunto representativo de los datos.
{kind=link}