Cross validation is a statistical method used to evaluate the performance of machine learning models. It is a technique that is used to validate the model's ability to generalize to new data, and it is especially useful when the model has few data points or when the data is imbalanced.
There are several types of cross validation methods, including:
-
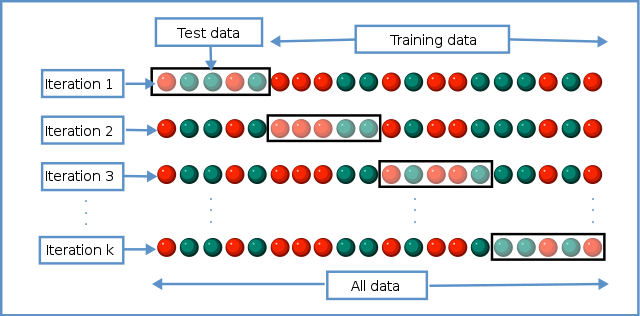
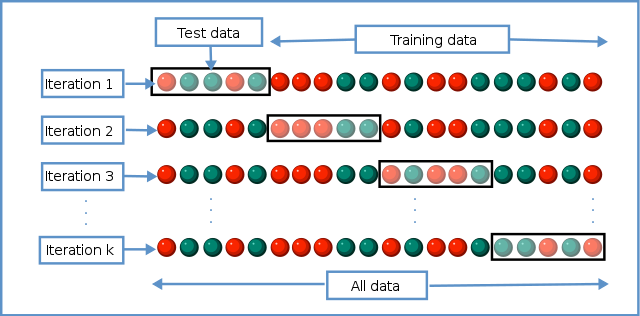
K-fold cross validation: This method involves dividing the data into k folds, where k-1 folds are used for training and one fold is used for testing. The process is repeated k times, with a different fold being used as the test set each time. The average performance across all k iterations is used to evaluate the model.
-
Stratified K-fold cross validation: This method is similar to K-fold cross validation, but it ensures that the distribution of classes in the folds is the same as the distribution in the overall dataset. This is especially important when the data is imbalanced, as it ensures that the model is tested on a representative subset of the data.
-
Leave-one-out cross validation: This method involves training the model on all but one data point, and then using that one data point as a test set. This process is repeated for every data point, resulting in a high number of iterations. It is computationally intensive, but it provides a very thorough evaluation of the model.
-
Repeated K-fold cross validation: This method involves repeating the K-fold cross validation process a number of times, with different random splits of the data each time. The average performance across all iterations is used to evaluate the model.
Cross validation is an important step in the machine learning process, as it helps to ensure that the model is robust and able to generalize to new data. It is particularly useful when the data is limited or imbalanced, as it allows the model to be tested on a representative subset of the data.
{kind=link}