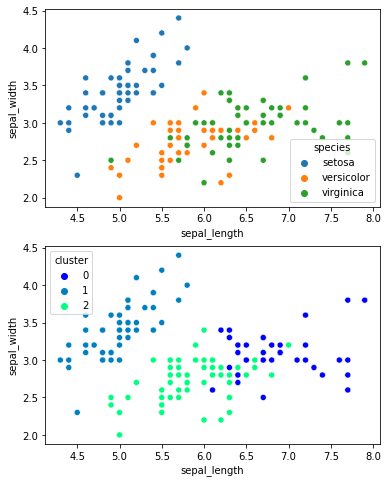
Clustering is a machine learning technique used to group data into sets or "clusters." Data within a cluster is similar to one another and different from data in other clusters. The goal of clustering is to find patterns or structures in the data without having a specific label or target variable in mind.
 There are many practical applications of clustering, including:
There are many practical applications of clustering, including:
-
Market segmentation: Customer data can be grouped into clusters based on similar characteristics or behaviors, allowing businesses to better understand their customers and how to effectively communicate with them.
-
Text analysis: Clustering of text documents can be used to organize large amounts of information and make it more easily accessible to users.
-
Spam detection: Clustering of emails can be used to detect and filter spam.
-
Recommendations: Applied to users or products can be used to personalize product or content recommendations online.
There are several clustering methods, including hierarchical clustering, partitioning clustering, and density-based clustering. Each method has its own advantages and disadvantages and is suitable for different sets of data and objectives.
Overall, clustering is a valuable tool for exploring and understanding data in a novel and sometimes surprising way. While it does not provide a definitive answer, it can provide important clues and is often the first step in the data analysis process.