Supongamos ahora que nuestro modelo de datos es un poco más complejo y está formado por dos tablas: la tabla anterior conteniendo información de ventas, y una segunda tabla con información sobre dónde se ha realizado cada venta (tabla que podemos llamar Geography):
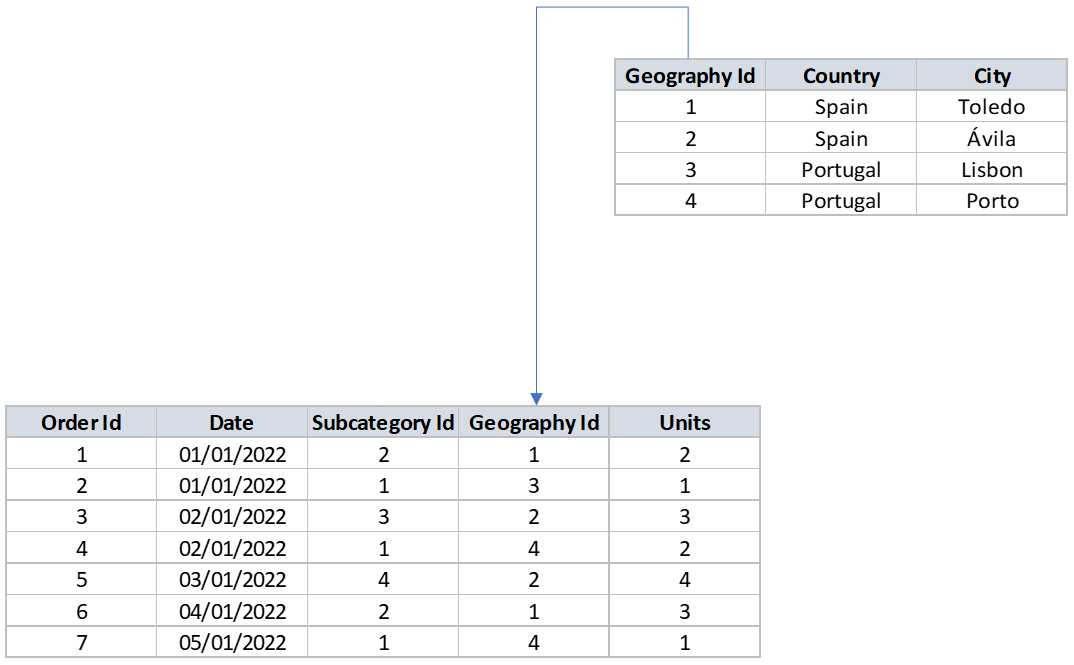
Estas tablas están relacionadas a través de los campos Geography Id que hay en ambas, lo que nos permite deducir que, por ejemplo, la segunda venta (la que tiene en el campo Order Id el valor 2) fue realizada en la ciudad de Lisboa, Portugal, pues ésta es la ciudad correspondiente al identificador Geography Id 3 que encontramos en la fila correspondiente a dicha venta.
Una vez más, si no hay motivos para pensar otra cosa, las tablas no estarían inicialmente siendo filtradas de forma alguna, por lo que el contexto de filtro sería describible diciendo que “todas las filas de las dos tablas son visibles”. Es decir, aplicando nuestro criterio de mostrar de amarillo o blanco las filas en función de su visibilidad, el contexto de filtro sería el siguiente:
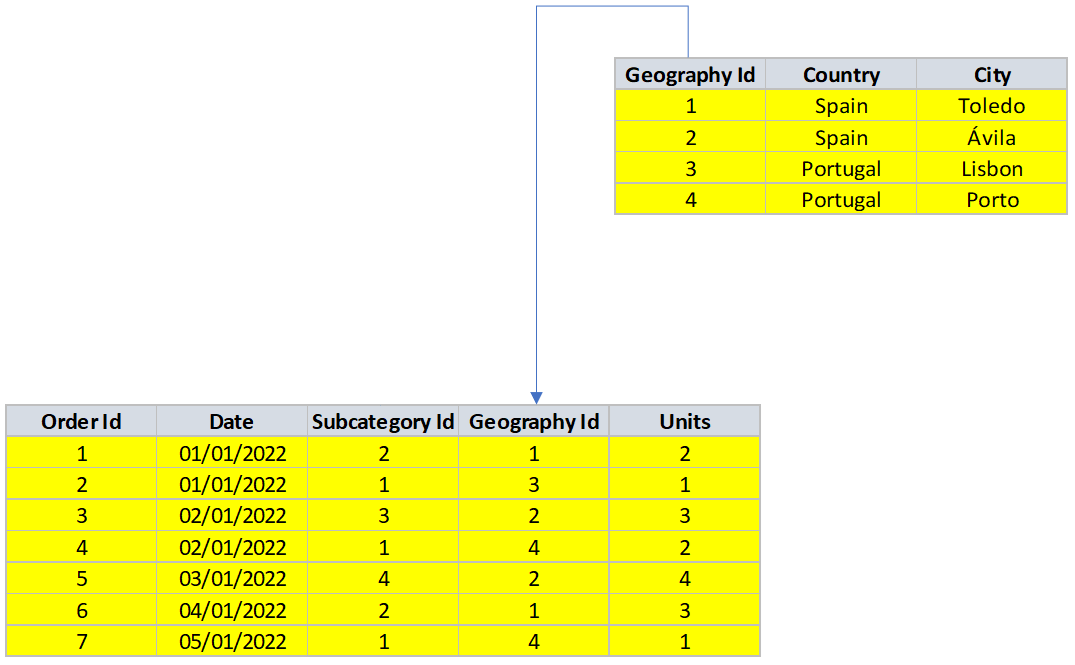
Como ya sabemos, cualquier operación aplicada a este modelo de datos incluiría todas sus filas: ¿Cuál es la suma de Units?: 16. ¿Y el valor mínimo del campo Date?: 1 de enero de 2022. ¿Y el valor máximo?: 5 de enero de 2022.