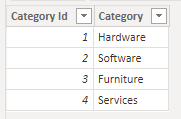
La tabla Category contiene un identificador de categoría y un nombre de categoría:
Supongamos que quisiéramos añadir a la tabla una columna calculada que contuviese un código de categoría (por ejemplo, “A” para “Hardware”, “B” para “Software”, etc.). Podríamos, sin duda, recurrir a varias funciones IF anidadas que fuesen comparando el nombre de la categoría de la fila siendo evaluada con las etiquetas “Hardware”, “Software”, etc., devolviendo los códigos adecuados en cada caso:
IF(
[Category] = "Hardware",
"A",
IF(
[Category] = "Software",
"B",
IF(
[Category] = "Furniture",
"C",
"D"
)
)
)
El resultado sería el esperado:
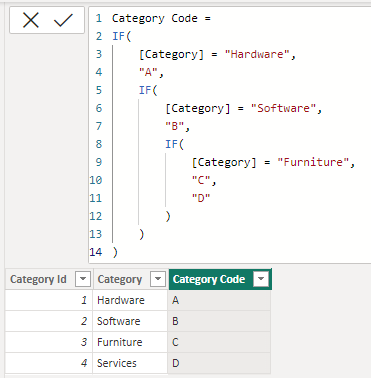
Sin embargo, a medida que aumenta el número de condiciones a evaluar, la expresión se hace cada vez más difícil de leer y de mantener.
En un caso como éste podemos recurrir a la función SWITCH. Esta función evalúa una expresión (el campo [Category] en nuestro ejemplo) y devuelve el resultado asociado a la primera coincidencia que encuentre en sus argumentos. Nuestra columna calculada quedaría del siguiente modo:
SWITCH(
[Category],
"Hardware", "A",
"Software", "B",
"Furniture", "C",
"Services", "D",
"n/a"
)
Vemos que el primer argumento pasado a la función es la expresión a evaluar (el valor de la columna [Category]) y después, por parejas, se pasan los valores a comparar con el resultado de la expresión y el resultado a devolver si se encuentra una coincidencia. Si el último argumento pasado a la función no tiene un resultado asociado, se considera el valor a devolver si no ha habido ninguna coincidencia (“n/a” en el código anterior), es decir, se considera el resultado por defecto.