Lasso -del inglés Least Absolute Shrinkage and Selection Operator- es un modelo lineal que penaliza el vector de coeficientes añadiendo su norma L1 (basada en la distancia Manhattan) a la función de coste:
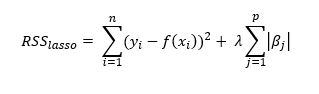
Lasso tiende a generar "coeficientes dispersos": vectores de coeficientes en los que la mayoría de ellos toman el valor cero. Esto quiere decir que el modelo va a ignorar algunas de las características predictivas, lo que puede ser considerado un tipo de selección automática de características. El incluir menos características supone un modelo más sencillo de interpretar que puede poner de manifiesto las características más importantes del conjunto de datos. En el caso de que exista cierta correlación entre las características predictivas, Lasso tenderá a escoger una de ellas al azar.
Esto significa que, aunque Ridge es una buena opción por defecto, si sospechamos que la distribución de los datos viene determinada por un subconjunto de las características predictivas, Lasso podría devolver mejores resultados.
Scikit-Learn implementa este algoritmo en la clase sklearn.linear_model.Lasso. Tal y como ocurría con Ridge, también puede entrenarse vía Gradient Descent usando la clase class sklearn.linear_model.SGDRegressor y especificando penalización l1 en este caso.