En cualquier caso, debemos saber que dicha convergencia solo está asegurada si las muestras del conjunto de entrenamiento son linealmente separables. Por ejemplo, si estamos trabajando en un dataset bidimensional (con dos características predictivas), deberá ser posible trazar una línea que separe las muestras en el plano, como en el ejemplo que estamos viendo, para el que existían infinitas líneas que podían servirnos:
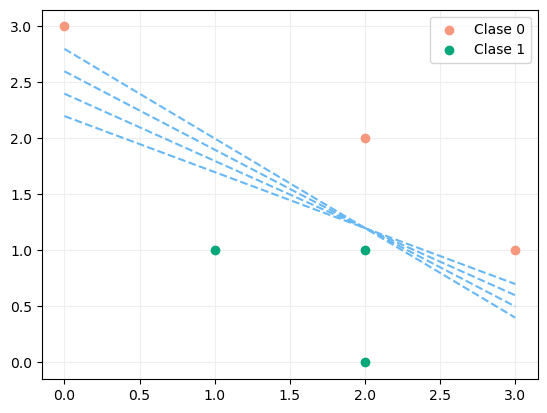
Si, por el contrario, los datos -llevados al plano- fuesen éstos:
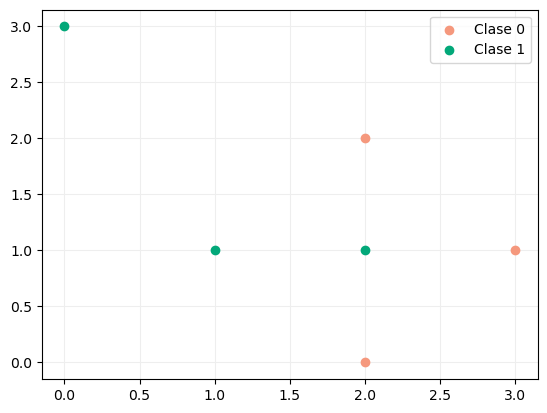
ya no serían linealmente separables y la convergencia del entrenamiento no estaría garantizada.
En un caso así, podríamos limitar el número de epochs durante los que se entrenaría la neurona, o podríamos establecer un cierto margen de error (es decir, asumir que ciertas muestras van a quedar mal clasificadas).