Los algoritmos de aprendizaje no supervisado son una herramienta importante en el campo del aprendizaje automático, y se utilizan para hacer predicciones o tomar decisiones basadas en datos. A diferencia de los algoritmos supervisados, que se entrenan utilizando datos etiquetados, los algoritmos no supervisados no tienen datos de entrenamiento etiquetados. En lugar de eso, utilizan la estructura inherente de los datos para aprender y hacer predicciones.
Un ejemplo común de un algoritmo de aprendizaje no supervisado es el clustering (agrupamiento), que se utiliza para dividir un conjunto de datos en grupos o clústeres basados en la similitud entre los datos:
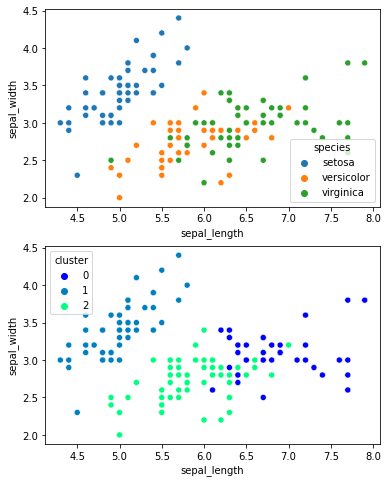
Otro ejemplo es la reducción de dimensionalidad, que se utiliza para reducir el número de características en un conjunto de datos mientras se mantiene la información importante.
Además del clustering y la reducción de dimensionalidad, los algoritmos no supervisados también se pueden utilizar para detectar patrones o tendencias en los datos y para realizar análisis de componentes principales. Los algoritmos no supervisados también se utilizan en aplicaciones de detección de anomalías y en la recomendación de productos.
En general, los algoritmos de aprendizaje no supervisado son una herramienta útil para hacer predicciones o descubrir patrones en datos sin etiquetar. Sin embargo, debido a que no utilizan datos de entrenamiento etiquetados, pueden ser menos precisos que los algoritmos supervisados en algunas aplicaciones. A pesar de estos posibles inconvenientes, los algoritmos no supervisados siguen siendo una herramienta importante en el aprendizaje automático y tienen una amplia gama de aplicaciones prácticas.