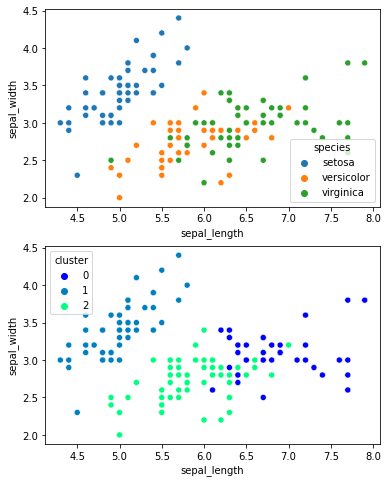
El clustering es una técnica de aprendizaje automático que se utiliza para agrupar datos en conjuntos o "clusters". Los datos en un cluster son similares entre sí y diferentes de los datos en otros clusters. El objetivo del clustering es encontrar estructuras o patrones en los datos sin tener una etiqueta o una variable objetivo específica en mente.
 Hay muchas aplicaciones prácticas del clustering, incluyendo:
Hay muchas aplicaciones prácticas del clustering, incluyendo:
-
Segmentación de mercado: los datos de clientes se pueden agrupar en clusters según sus características o comportamientos similares, lo que permite a las empresas entender mejor a sus clientes y cómo comunicarse con ellos de manera más efectiva.
-
Análisis de texto: el clustering de documentos de texto se puede utilizar para organizar grandes cantidades de información y hacerla más fácilmente accesible para los usuarios.
-
Detección de spam: el clustering de correos electrónicos se puede utilizar para detectar y filtrar spam.
-
Recomendaciones: aplicado a usuarios o productos se puede utilizar para personalizar las recomendaciones de productos o contenidos en línea.
Existen varios métodos de clustering, incluyendo el agrupamiento jerárquico, el agrupamiento por partición y el agrupamiento basado en densidad. Cada método tiene sus propias ventajas y desventajas y es adecuado para diferentes conjuntos de datos y objetivos.
En general, el clustering es una herramienta valiosa para explorar y comprender los datos de una manera novedosa y a veces sorprendente. Aunque no proporciona una respuesta definitiva, puede proporcionar pistas importantes y a menudo es el primer paso en el proceso de análisis de datos.