Un enfoque sencillo de selección de características es aquel que selecciona solo las características cuya varianza supera un cierto umbral. La idea detrás de este enfoque es que, si la varianza de una variable es pequeña, las probabilidades de que el valor contenido en ella sea el mismo -o muy parecido- son elevadas, por lo que aportará poco al algoritmo.
Veamos un sencillo ejemplo. Supongamos que partimos del siguiente dataset:
[[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]],
columns = list("ABC")
)
data
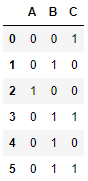
Podemos comprobar visualmente que casi todos los valores de la característica A son 0. Veamos las varianzas:
B 0.222222
C 0.250000
dtype: float64
Obsérvese que estamos mostrando la varianza de la población (asignando al parámetro ddof el valor 0).
Efectivamente, la característica A tiene el valor más bajo de las tres varianzas. Podríamos seleccionar aquellas que superasen un umbral mínimo con la clase VarianceThreshold de Scikit-Learn. Comenzamos importándola:
Ahora la instanciamos fijando como umbral (parámetro threshold) el valor 0.2, por ejemplo:
Por último, la aplicamos a nuestro dataset usando el método .fit_transform():
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]], dtype=int64)
Vemos que el resultado es un array NumPy. Podemos visualizar las características que han superado el umbral con el método .get_feature_names_out():
aunque el resultado devuelto no son índices ni los nombres de las características (lo que no facilita mucho el trabajo).
Más útil es el método .get_support(), que devuelve un booleano indicando si la característica en cuestión superó o no la selección:
Esto nos permite mostrar, por ejemplo, los nombres del DataFrame de las características seleccionadas:
También podemos visualizar las varianzas de las variables mediante el atributo .variances_:
y vemos que estas varianzas son calculadas sobre la población, no son muestrales.
El valor por defecto del parámetro threshold es 0, lo que significa que, salvo que especifiquemos otra cosa, este selector eliminará aquellas columnas en las que sus valores sean todos iguales.