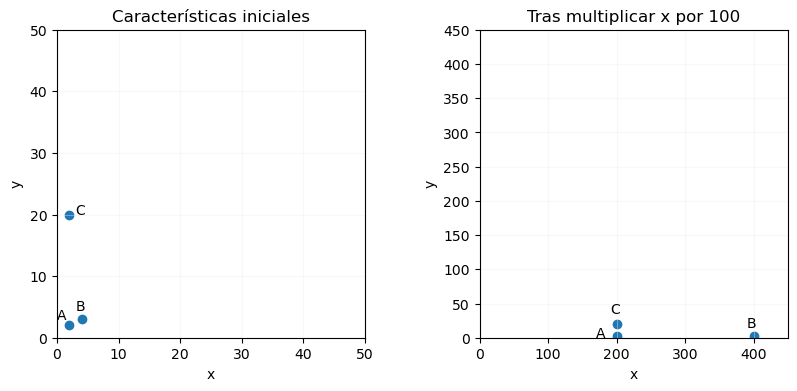
Como se ha comentado, hay algoritmos muy sensibles al escalado de los datos: mientras que un árbol de decisión se va a describir por reglas del tipo "si el valor de la característica x es mayor o igual que n", devolviendo el mismo resultado con independencia de que los valores de la característica x mencionada aumenten o disminuyan de forma proporcional, otros algoritmos como las redes neuronales van a dar diferente importancia a una característica o a otra en función de la escala que tengan sus valores (además de poder suponer otras dificultades al entrenamiento). Un claro ejemplo de esto es el algoritmo K-Nearest Neighbors, que asigna una clase a un elemento a partir de las clases de los puntos "más próximos". En la imagen de la izquierda que se muestra a continuación, por ejemplo, el punto A = (2, 2) puede ser considerado próximo a B = (4, 3) y lejano a C = (2, 20). Pero si la primera de estas dos dimensiones o características se multiplica por 100, los puntos anteriores se convertirían en (200, 2), (400,3) y (200, 20) respectivamente, cambiando totalmente el concepto de "proximidad":
Para aplicar un escalado semejante a las diferentes características tenemos dos enfoques diferentes: el escalado y la normalización. El escalado va a transformar los valores de las características de forma que estén confinados en un rango [a, b], típicamente [0, 1] o [-1, 1]. La normalización va a transformar las características de forma que todas compartan un mismo valor medio y una misma desviación media, por ejemplo.
Scikit-Learn ofrece diferentes escaladores (llamados así con independencia del enfoque aplicado).
Es importante mencionar que el escalador deberá entrenarse solo con los datos de entrenamiento para evitar fugas, y que deberá aplicarse de igual forma tanto a los datos de entrenamiento como a los de validación y prueba (si existen).
Revisemos algunos de éstos.