En ocasiones debemos trabajar con datasets que incluyen valores nulos: valores incompletos, corruptos, etc. Por ejemplo, visualicemos el dataset correspondiente al último viaje del Titanic proveído por la librería seaborn:
titanic = sns.load_dataset("titanic")
titanic.sample(5, random_state = 1877)
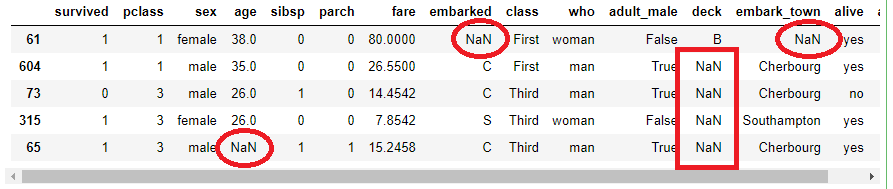
En la imagen anterior, todos los NaN ("Not a Number") son valores nulos que pueden impedirnos aplicar ciertos algoritmos (la mayoría, de hecho). Las posibles soluciones para resolver este problema incluyen:
- Eliminación de muestras o de características que incluyan valores nulos
- Reemplazo por un valor (la media, mediana, moda, etc.)
- Asignación de una categoría exclusiva
- Predicción de los valores nulos