Otro de los métodos que podemos aplicar es entrenar un modelo a partir de las características predictivas que no incluyan valores nulos para predecir los valores nulos de otra columna.
Recordemos el número de valores nulos por característica:
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
Vemos que la característica "embark_town" incluye dos valores nulos que podríamos plantearnos predecir a partir de, por ejemplo, las características "pclass", "sibsp", "parch", "fare" y "adult_male", que no incluyen valores nulos.
Comenzamos, por lo tanto, extrayendo los datos con los que entrenar el modelo (muestras sin nulos en el campo embark_town):
titanic.embark_town.notnull(),
["pclass", "sibsp", "parch", "fare", "adult_male", "embark_town"]
]
Ahora tendríamos que extraer las características predictivas y las etiquetas:
y = train["embark_town"]
Entrenemos, por ejemplo, el algoritmo Random Forest:
Para validarlo, podemos usar validación cruzada:
Obsérvese que estamos ejecutando el método .mean() del array devuelto por cross_val_score. En media se están prediciendo correctamente el 82.7% de las muestras.
Ahora entrenemos el modelo:
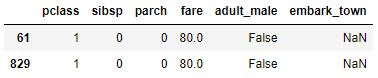
y extraigamos el dataset sobre el que realizar la predicción (muestras en la que el campo embark_town toma un valor nulo):
titanic.embark_town.isnull(),
["pclass", "sibsp", "parch", "fare", "adult_male", "embark_town"]
]
data
Ya podemos realizar la predicción:
prediction
Coincide que las dos predicciones son de la ciudad de Cherbourg.
Por último, no resta más que convertir la predicción en una Serie Pandas para poder darle los índices correctos (los incluidos en el DataFrame data) y usar el método .fillna() para realizar la imputación:
prediction
829 Cherbourg
dtype: object