Algo más cómodo es el uso de Pandas. Recordemos los primeros registros del dataset Titanic:
titanic.head()

Para aplicar la codificación One Hot Encoding, bastaría con pasar a la función pd.get_dummies() la Serie Pandas a codificar. Por ejemplo, podemos codificar el puerto de embarque (columna "embarked") con el siguiente código:
data
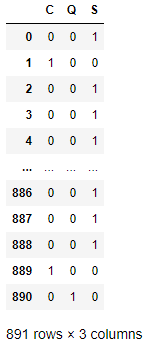
Como vemos, el resultado es un DataFrame Pandas que incluye tanto los índices de fila como de columna.
Aquellos registros que contenían nulos, reciben como codificación [0, 0, 0], cosa que podemos comprobar si identificamos sus índices:
index
y mostramos las filas correspondientes de la estructura data que hemos creado:
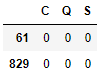
En todo caso, es posible forzar la creación de una columna independiente para estas muestras dando al parámetro dummy_na el valor True:
data
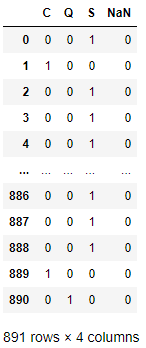
Ahora, las muestras que incluían nulos han sido codificadas de la siguiente forma:
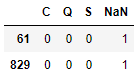
Para sustituir la columna original con la estructura obtenida podemos volver a recurrir a la función pd.concat():
titanic.drop("embarked", axis = 1),
data
], axis = 1)
titanic.head()
