Si pasamos a la función pd.get_dummies() un DataFrame con más de una columna, se aplicará la codificación One Hot Encoding a todas ellas. Por ejemplo:
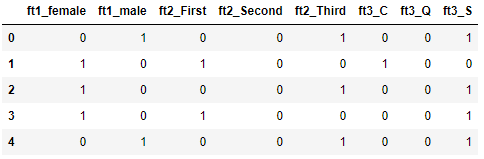
data = pd.get_dummies(titanic[["sex", "class", "embarked"]])
data.head()
data.head()
Como vemos, cada una de las columnas generadas recibe como nombre el nombre de la característica de la que procede, seguido del valor representado. Este comportamiento es controlable usando el parámetro prefix. Por ejemplo, podríamos asignar un prefijo único a todas las columnas generadas:
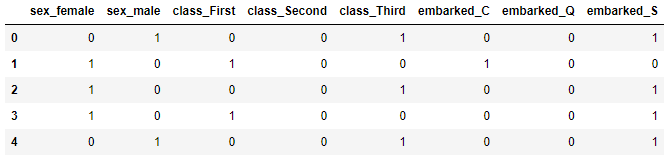
data = pd.get_dummies(titanic[["sex", "class", "embarked"]], prefix = "feature")
data.head()
data.head()
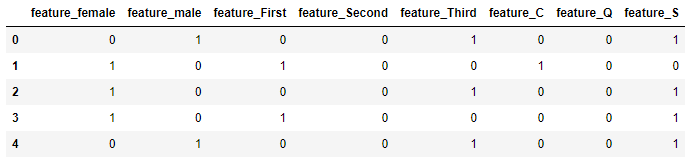
O especificar un prefijo distinto para cada grupo de columnas:
data = pd.get_dummies(titanic[["sex", "class", "embarked"]], prefix = ["ft1", "ft2", "ft3"])
data.head()
data.head()