Los árboles de decisión en Scikit-Learn (y los algoritmos basados en éstos) dan acceso a la importancia de las características a través del atributo .feature_importances_, siendo calculada la importancia de una característica como la reducción total (normalizada) del criterio de medición que se esté usando ("gini", "entropy" o "log_loss").
Por ejemplo, apliquemos el árbol de decisión implementado en la clase DecisionTreeClassifier sobre el dataset wine que hemos cargado. Importamos la clase y la instanciamos fijando como profundidad máxima, por ejemplo, 4:
Validemos, en primer lugar, el modelo usando validación cruzada:
Se clasifican correctamente el 90% de las muestras.
Ahora entrenemos el algoritmo:

y mostremos la importancia relativa dada a cada característica:
importances
0. , 0. , 0. , 0. , 0.11599466,
0. , 0. , 0.82373707])
Podemos mostrar estos valores en un gráfico de barras: Para ello extraemos los nombres de las características:
y los índices de las importancias dadas, ordenadas de mayor a menor:
indices
Ahora ordenamos los nombres de las características y los valores obtenidos:
sorted_feature_names = feature_names[indices]
Por último, mostramos la gráfica:
ax.barh(y = sorted_feature_names, width = sorted_importances, zorder = 10)
ax.grid(color = "#EEEEEE", zorder = 0)
ax.set_xlabel("Feature importance")
ax.set_ylabel("Feature name")
plt.show()
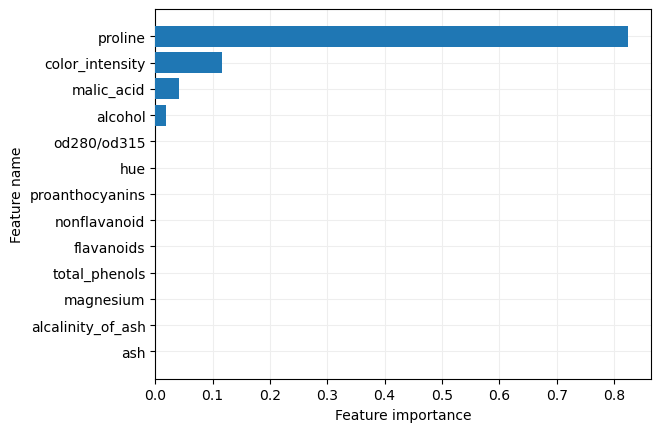
Si nos quedamos solo con las características que han recibido alguna importancia:
features
y validamos el modelo resultante de entrenar un árbol de decisión solo a partir de ellas:
comprobamos que, en este caso, el porcentaje de muestras clasificadas ha aumentado con respecto al modelo previo.