Support Vector Machines (SVM) son un conjunto de métodos de aprendizaje supervisado usados en clasificación, regresión y detección de anomalías. Fueron desarrollados por Vladimir Vapnik y su equipo en los años 60, aunque no fue hasta los años 90 que comenzaron a utilizarse.
Para entender la filosofía que hay detrás de este algoritmo, supongamos que queremos clasificar las siguientes muestras en un espacio de dos dimensiones:
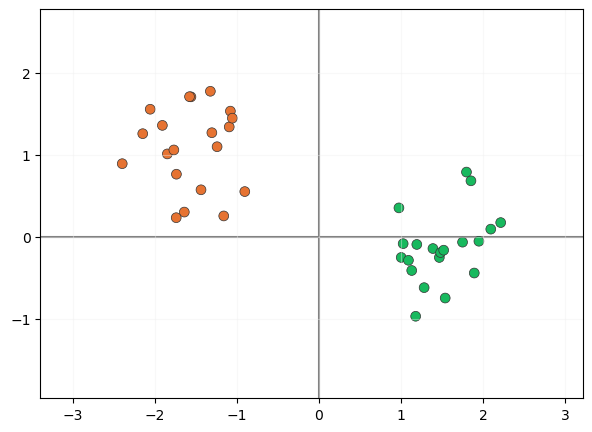
Por supuesto, muchos clasificadores lineales podrían realizar esta tarea, por ejemplo, aquel que fije el siguiente límite de decisión entre ambas clases:
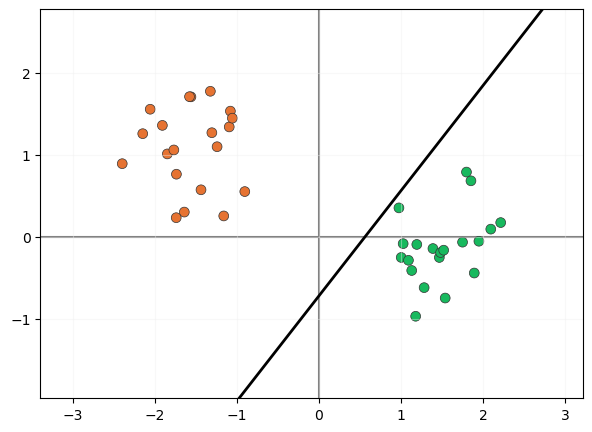
Sin embargo, estaremos de acuerdo en que este clasificador no parece demasiado seguro, pues si tiene que clasificar una muestra próxima al clúster de muestras verdes pero al otro lado del límite de decisión:
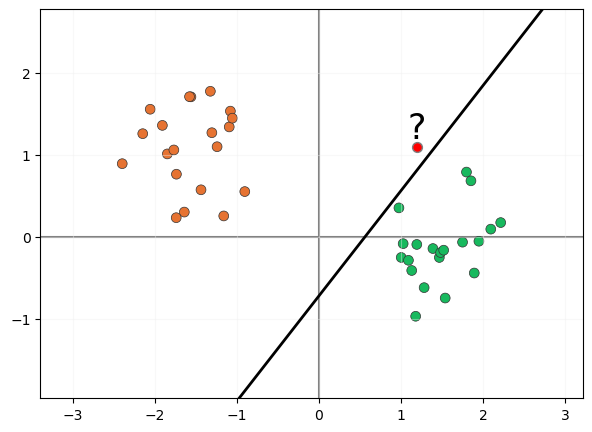
la consideraría perteneciente al clúster de muestras naranjas, lo que no parece muy lógico considerando su posición.