El uso de las llamadas funciones de error (error functions, también llamadas funciones de coste, cost functions o funciones de pérdida, loss functions) se remonta a los primeros días del aprendizaje automático, específicamente al trabajo del estadístico y matemático Ronald A Fisher en la década de 1920.
Fisher desarrolló el concepto de función de verosimilitud, medida de la probabilidad de que los datos observados se generen a partir de un modelo estadístico dado.
El Perceptrón de Rosenblatt utilizaba una función de coste conocida como error de clasificación, que simplemente se basa en la medida del número de errores de clasificación que comete el modelo en el conjunto de datos siendo analizado, siendo el objetivo del algoritmo el minimizar el resultado de esta función de coste.
Sin embargo, la función de coste del Perceptrón no era diferenciable, lo que implica que no era posible aplicar técnicas de optimización avanzadas para ajustar los pesos de la neurona.
Bernard Widrow y Tedd Hoff involucraron en su Adaline una función de coste diferenciable llamada SSE, Sum of Square Errors (suma de errores cuadráticos).
Aun cuando en el artículo científico publicado por estos investigadores en 1960 no se menciona explícitamente la fórmula usada para esta función, se suele asumir la siguiente:
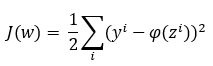
Es decir, consideramos las diferencias entre las etiquetas de las muestras, yi, y los valores devueltos por la función de activación, Φ(zi), y sumamos los cuadrados de los resultados. Finalmente, se divide entre dos simplemente para simplificar los resultados obtenidos cuando se derive esta fórmula.
Obsérvese que, lógicamente, el resultado de la función coste depende de los valores de los pesos.